# 如影数字人/如影声音复刻采集标准
人物采集采集建议重点阅读第1,5,6,7章节。
# 1. 快速数字人/普通数字人采集标准
# 1.1 拍摄环境&设备
# 1.1.1 拍摄环境要求
安静的环境:拍摄时没有外部声音干扰录音,包括其他人声,空调、电扇等电器声以及其他噪音或震动
干净的拍摄背景:
- 不可出现动态背景(视频、动画等)
- 不可出现反光、透明、半透明材质的背景
- 拍摄背景中不可出现直接的光源,比如采光窗户或发光的灯泡
- 建议绿幕拍摄(数字人视频可换背景)
依据拍摄质量要求配置相应光源,整体光照均匀,背景环境无明显阴影

# 1.1.2 拍摄设备要求
- 使用可拍摄1080P以上分辨率的单反相机或摄像机拍摄(建议使用1080*1920分辨率竖屏拍摄)
- 配置可连接单反相机(或摄像机)的麦克风,麦克风不要夹在模特身上,建议放置在离模特尽可能近的镜头之外的位置,拍摄前提前确认采集的声音清晰无底噪
- 建议配置提词器(或使用iPad安装提词APP)
# 1.1.3 模特服化道准备
拍摄前清洁面部(男士注意修剪胡须),依据需求适当化妆
整体妆容、服装、道具以最终数字人想要呈现的效果为准,但应避免如下情况:
- 避免过于宽松的发型
- 避免有吊坠的耳饰或其他饰物
- 避免发型或过大的眼镜遮挡模特下半脸
- 避免反光过强的唇彩或眼影
# 1.2 拍摄采集
# 1.2.1 采集流程
- 拍摄采集的过程整体分为两个部分,静默画面与口播画面
- 静默画面:整个采集流程前30秒为静默画面采集,模特面向镜头保持嘴部闭合状态(可以模拟倾听的状态,可以有自然得体的轻微点头及微笑,但不宜过多;静默30秒需始终保持嘴唇闭合状态)
- 口播画面:静默画面拍摄够30秒后,保持光照环境不变,保持模特pose不变,进入口播画面采集阶段(仅用于短视频制作的数字人采集5分钟口播画面即可;用于直播的数字人可以适当延长口播画面采集时长,建议可以录制20-30分钟)
- 在口播画面采集阶段,口播稿内容、模特语速、情绪、表情、手势都尽量模拟将来数字人要应用的典型场景(比如将来数字人主要用于旅游产品直播售卖,那么直接使用旅游产品直播稿,直播卖货的语速、情绪、表情、手势来完成采集,尽量模拟真实的使用场景)
# 1.2.2 采集过程注意事项
环境相关:
- 采集过程中保持现场安静,拍摄时没有外部声音干扰录音,尤其不可出现第二个人的声音;尽量避免空调、服务器等设备噪音,避免场地其他噪音或环境震动
设备相关:
- 建议以1080*1920分辨率,25fps,竖屏录制
- 拍摄时使用连接到相机的麦克风同步录制现场声音,确保采集的声音清晰无底噪
模特相关:
- 模特妆容准备完毕,请模特入镜就位(按具体拍摄要求坐姿或站姿)
- 如绿幕拍摄,模特背部距离绿幕2m以上,避免绿幕浸染(导致后期抠像效果差)
- 请确认模特面部光照均匀,无强阴影(尤其是鼻子下方,鼻侧,脖子)

- 请确认模特所处位置位于画面中合适位置,且不会因拍摄时的肢体动作,导致身体或手部超出镜头范围

- 拍摄时,模特平视面向镜头,避免大角度仰视、俯视或侧向、背向镜头

- 模特说话时口齿清晰,口型保持饱满。停顿时嘴巴闭合,不留缝隙;避免“张嘴,但不出声”的情况
- 断句或两句间隔时也尽量确保嘴部闭合,不留缝隙
- 提词器文本并不是严格逐字逐句朗读,在保持适当情绪、表情的状态下,允许模特在播报期间,衔接上下文自由发挥念词
- 若口播视频采集过程中,模特出现停顿,读错,失误,或其他意外,可完全闭嘴2-3秒后继续朗读(但需要避免笑场、咳嗽、清嗓子以及其他发出无关声音的情况)
- 采集过程,模特可以有自然肢体语言;但身体动作不要过大,避免肩部和颈部的大幅度动作
- 增加一些手势可以让生成的模型更自然,但需要确保手势不要遮挡脸部
- 整个采集过程,保持模特的身体和手势在视频框内
- 整个口播视频采集过程,表情和情绪请模仿想要的数字人场景,比如之后数字人主要用于直播带货,采集时就以直播带货主播的情绪与状态去录制
# 1.2.3 使用手机拍摄采集注意事项
使用iPhone拍摄请尽量关闭HDR,因为iPhone的HDR算法非开源算法,无法将视频中的HDR颜色表达完全还原;
iPhone输出的格式为mov格式,请转为mp4格式后并确认整体视频效果后,上传提交进行人物生成训练;
# 1.2.4 绿幕采集拍摄采集注意事项
绿幕分割的原理是去绿,将视频中绿色的部分去除,所以使用绿幕分割需要注意不要有绿色、反绿、透绿的情况反发生,否则会将绿色扣掉,会出现一些错误的分割情况;
- 绿幕拍摄请保证只有一种绿色,多种绿色影响分割效果;
- 绿幕拍摄请保证光线效果,做到绿色幕布区域都是绿色,但是人像物体等非绿幕区域不要有绿色,且不要有任何反绿,透绿,等现象;
- 模特或者非绿幕区域不要有透明,反光等情况,否则可能会将绿色反色,影响分割效果;
如果拍摄前或者拍摄过程中不确定绿幕效果,请参考下一章节"提前预览视频绿幕效果"章节内容,提前拍摄一段视频来确认绿幕效果。
# 绿幕问题相关以及错误示例:
- 绿幕区域保证纯绿色,下图左上角和头顶部有黑色物体、黑点

- 绿幕区域保证纯绿色:下图顶部、底部有非绿色区域

- 裙子缝隙处,有绿色阴影,会影响效果,尽量避免有可能出现阴影的区域;

- 裙子缝隙处,有绿色阴影,会影响效果,尽量避免有可能出现阴影的区域;

- 受光线影响,底部鞋子中间区域可能会有黑色阴影,需要规避,不然黑绿色分割会出现问题;

- 避免反绿,反绿基本上无法有较好的绿幕效果,下图中衣服几乎受强光打到绿幕导致反光的影响,身上都是绿色,很难分割出比较好的效果;

- 避免透明物体,下图眼镜片有绿色透过去了,手机膜亮面会反绿,都会造成分割错误

- 避免反绿,下图鞋子有反绿,造成鞋子会被替换为背景图

- 避免两种绿色,下图主要是身上有反绿,同时又因两种绿色,无法非常合适地输出一个好效果。建议避免双色绿色的拍摄

- 避免剪辑后的图像有黑边问题:原视频拍摄一般没问题,但是部分绿幕视频被剪辑软件处理后,边缘有非绿色的色条(有时候只有1像素的黑边肉眼是无法看出来的,在最终合成视频时才发现有错误黑边问题)

- 支持蓝幕、其他色幕布颜色分割,但是效果不如绿幕好,建议使用绿幕拍摄

# 1.2.5 数字人采集视频验收标准
请严格按照以下项目自检,保证视频符合要求,不然会出现任务训练失败的情况:
人脸缺失:确保每一帧不能有人脸丢失,不要手或者物品遮挡人脸已经唇部;
多人脸:确保每一帧都不能有两张人脸(譬如海报中的人脸入境可能会导致失败);
不要有任何一帧存在有手或者其他物体遮挡唇部的场景,避免发型或过大的眼镜遮挡模特下半脸 ,数字人仅仅是口型生成,唇部周边区域如果有眼镜框可能导致口型生成错误;
大角度人脸:人脸角度建议30°以内,大角度(45°或更多)支持识别,但是有一定概率会失败。大角度走动示例视频 (opens new window)
非连续帧:不连续的帧如果保证每帧都有人脸不会失败,但是训练后的结果会出现跳帧情况;如果非连续帧出现人脸缺失会导致任务失败;
格式要求MP4;mov格式不支持;
分辨率推荐使用1080P,支持4k;
FPS要求为25,若不是25,会将FPS强制转为25FPS;
视频中不要出现外部声音,尤其不可出现第二个人的声音;
尽量避免空调、服务器等设备噪音,避免场地其他噪音或环境震动;
绿幕拍摄的视频注意不要有任何反光的情况出现;如银首饰,亮面眼镜框,亮面腰带等;
注意打光,不要让人物的身上,或者非绿色物体有反绿的现象发生;如果出现反绿会很影响绿幕分割效果,后续会详细讲解提升绿幕效果的方式;
不可出现动态背景(视频、动画等);不可出现反光、透明、半透明材质的背景;
避免反光过强的唇彩或眼影可能会影响绿幕分割效果,唇部生成效果;
# 1.3 提前预览视频绿幕效果
使用PAAS平台预览绿幕效果
# 1.3.1 图片绿幕效果预览
使用PAAS账号登录平台;
点击顶部"人物模型"—"绿幕效果预览;
点击左侧"图片绿幕效果预览";
填入任务名称,并上传需要确认绿幕效果的图片或者链接,背景色可以设置一些容易看出问题的效果色,如:

点击"预览效果"即可创建图片绿幕效果预览任务;
成功后,可以点击预览图片,查看效果;也可以点击右下角的"返回"—"任务类型"—"图片绿幕效果预览",查看任务返回结果;
若效果不符合要求可以通过调参更改绿幕效果;
# 1.3.2 视频绿幕效果预览
使用PAAS账号登录平台;
点击顶部"人物模型"—"绿幕效果预览;
点击左侧第二个"视频绿幕效果预览";

填入任务名称,并上传需要确认绿幕效果的视频或者链接,背景色可以设置一些容易看出问题的效果色,如:
点击"预览效果"即可创建图片绿幕效果预览任务;
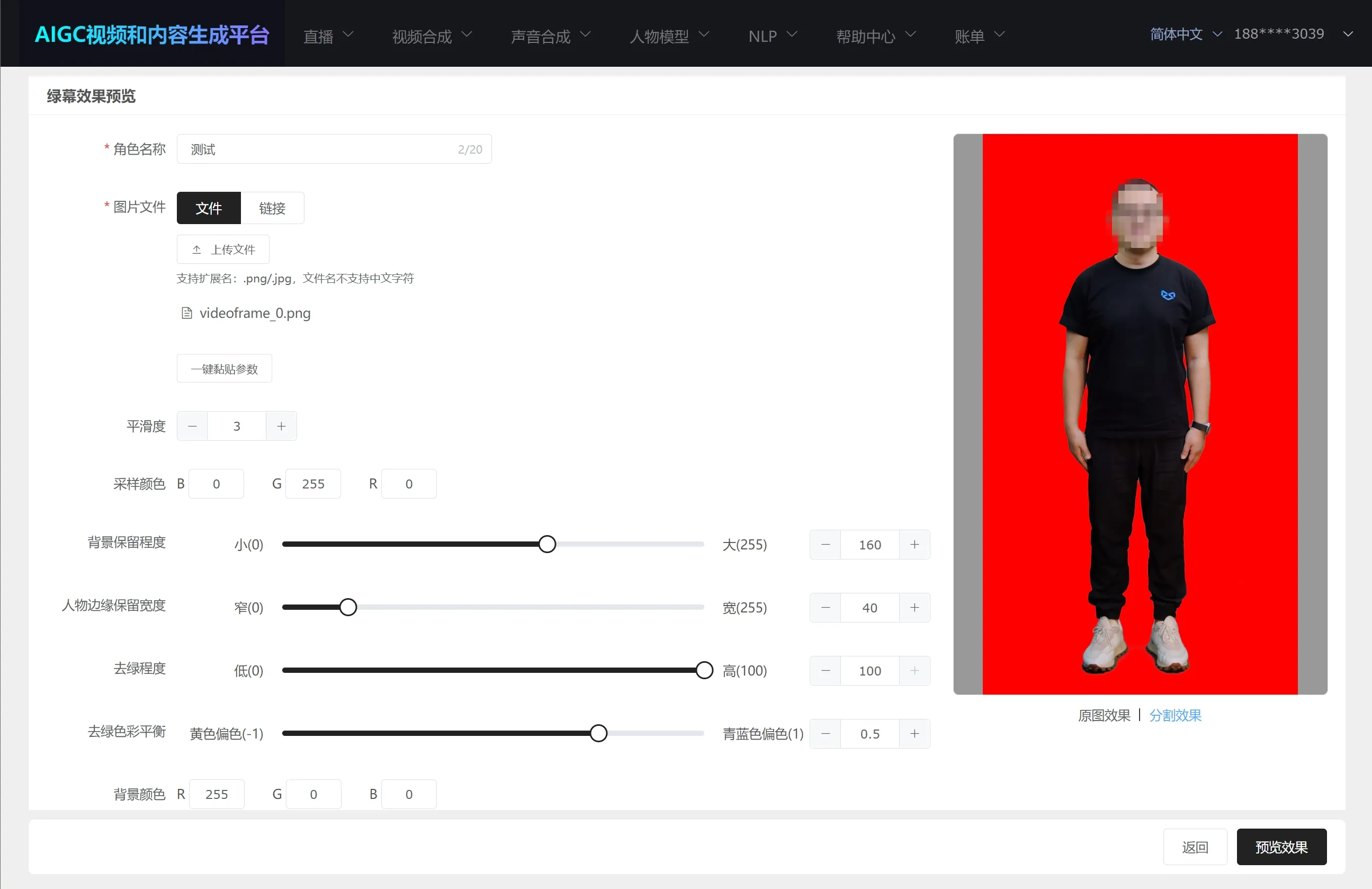
成功后,可以点击预览图片,查看效果;也可以点击右下角的"返回"—"任务类型"—"视频绿幕效果预览",查看任务返回结果;
若效果不符合要求可以通过调参更改绿幕效果;
# 1.3.3 绿幕参数说明以及应用到数字人模型训练中
在创建任务或者任务完成后,都有"一键复制参数",具体参数释义如下:
{
"greenParamsRefinethHBgr": 160,//背景保留程度
"greenParamsRefinethLBgr": 40,//人物边缘保留宽度
"greenParamsBlurKs": 3,//平滑度
"greenParamsColorbalance": 100,//去绿程度
"greenParamsSpillByalpha": 0.5,//去绿色彩平衡
"greenParamsSamplePointBgr": [//采样颜色
0,
255,
0
],
"greenParamsSampleBackground": {//背景颜色
"color": [
255,
0,
0
]
}
}
获取参数后,可以在训练人物形象或者更新人物形象时使用。
# 1.3.4 移动端绿幕效果确认方式
若只是简单粗略的确认现场效果,也可以使用我们的移动端绿幕效果确认软件,但是最终效果请以我们平台效果确认为准。
使用流程如下:
请先联系我们商务或者售后同事,申请试用我们的Effects Demo;
下载安装Effects Demo后,进入首页,点击"特效";
选择"分割"item;
可以切换到后置摄像头,然后对准绿幕环境;
点击绿幕分割可以确认效果,背景图有默认的3张,也可以找手机的某张图片作为背景图,确认效果;

# 2. 精品数字人采集标准
# 2.1 拍摄采集要求
模特相关:
- 采集视频总长度5分钟左右,无变化。
- 采集过程中模特的动作由两部分构成:前30秒的静默画面,后4分半分左右的口播画面。无变化。
- 将静态部分身体姿势设定为默认姿态,整个静态部分的拍摄以默认姿态为主,可以模拟倾听的状态,可以有自然得体的轻微点头及微笑,但不宜过多;静默30秒需始终保持嘴唇闭合状态。 =增加默认姿态概念= 。
静态画面示意


- 口播画面的开始要求从默认姿态开始。在做一些身体动作,手臂动作后,需要模特回归到默认姿态(身体姿势一致,手臂位置一致,手部动作一致)。一般情况下,模特从默认姿态->做动作->回归默认姿态的时间控制在10秒内比较合适,。回归默认姿势后即可开始下一个动作,以此循环,在完成业务动作后不断回归到默认姿势。
- 进入口播画面的动作

- 口播画面中的动作1

- 恢复到默认状态

- 口播画面中的动作2

- 恢复到默认状态

# 2.2 精品数字人验收标准
请严格按照以下项目自检,保证视频符合要求,不然会出现任务训练失败或者效果不好的情况:
请参考2.5小章节,必须先符合普通数字人采集验收标准;
回归默认姿势时,每次的静默姿势都要一致,请务必准确回到原位置。
# 3. 动作编辑数字人采集标准
# 3.1 视频要求
动作编辑数字人的视频要求输出两个部分的视频:
标准数字人训练视频:用于口型训练,要求时长3分钟半,其中前面30秒静默闭口状态,3分钟说话状态;
动作编辑训练视频:用于不同的动作编辑训练,要求比较严格,请务必按扎以下要求进行拍摄录制,否则会出现效果不符合预期的情况; 动作编辑示例视频 (opens new window)
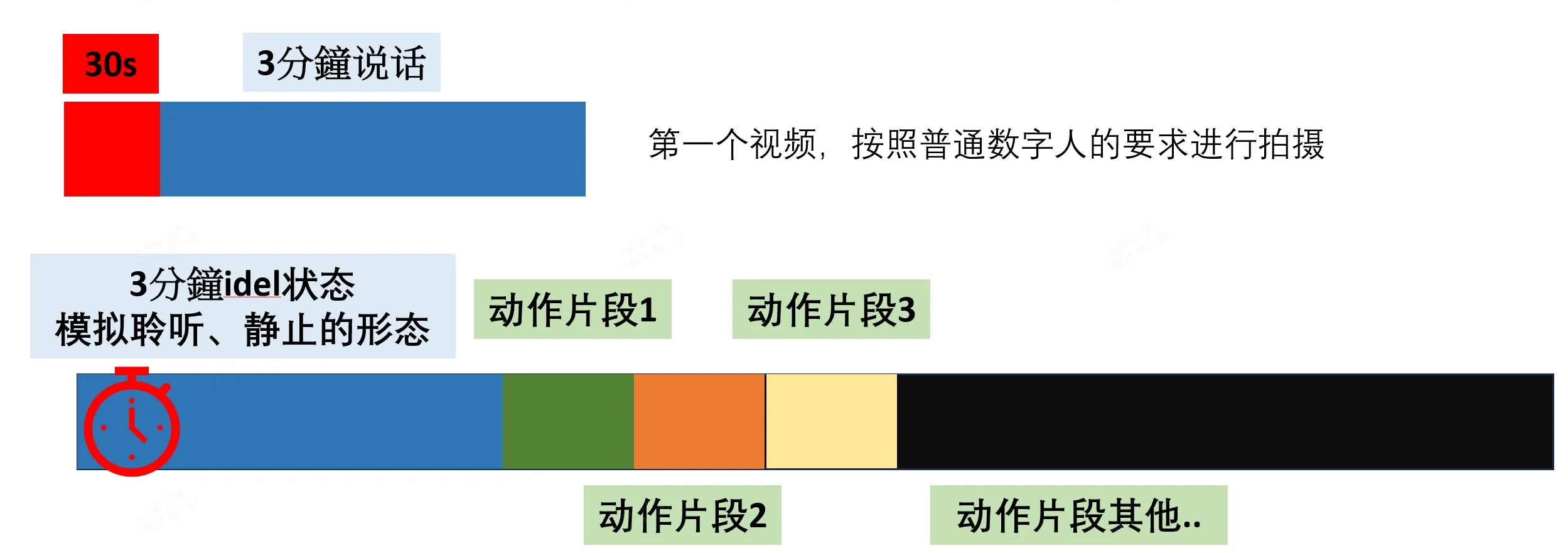
# 3.2 拍摄要求
标准数字人训练视频部分用于口型训练,拍摄方式和普通数字人拍摄方式一致;
标准数字人训练视频的人物姿态、相机状态、场景与动作编辑训练视频必须保持一致。
动作编辑训练视频分为idle动作,普通动作1,普通动作2,普通动作3,普通动作4,普通动作N..等动作。要求每个动作的开始和结束动作和idle测保证完全一致。这点非常关键,因为如果每次做完动作没有回归到idle状态,后期动作编辑展示时会出现错误。对拍摄模特要求较高,请尽量保证一致;
建议idle动作的长度在3分钟以内,其他动作的长度在10秒钟以内,推荐3秒左右,具体case见实际操作指引;
动作编辑训练视频,对环境音不做任何要求,可以有背景杂音,因为只会使用当前视频中的动作视频内容;
idel动作,后续不同的动作,可以分开拍摄,但是最终提交是需要合并成一个视频进行提交;
因为拍摄难度较大,建议提前准备好拍摄脚本,提前与模特沟通并演练好,示例脚本如下:
| 拍摄内容 | 时间 | 参考效果 | ||
|---|---|---|---|---|
| 1 | 基础口型拍摄 | 5分30秒 | 标准同之前旧版本 | |
| 2 | idle静态动作拍摄 | 开始:35.4结束:37.32 |  | 头部需要自然呼吸感动一动,模拟聆听别人问题的状态 |
| 3 | idle-右手挥手你好- idle | 开始:8.5结束:11.4 |  | |
| 4 | idle-右手向右展示- idle | 开始:26.64结束:29.32 |  | |
| 5 | idle-右手说话强调-idle | 开始:19.4结束:23.92 |  | |
| 6 | idle-右手向前-idle | 开始:14.88结束:17.92 |  | |
| 7 | idle-右手向上-idle | 开始:32.52结束:35.48 |  | |
| 8 | idle-右手食指着重-idle | 开始:37.48结束:43 |  | |
| 9 | idle-右手点赞-idle | 开始:47.12结束:49.56 |  | |
| 10 | idle-右手OK-idle | 开始:53.56结束:55.72 |  | |
| 11 | idle-右手比心-idle | 开始:59.8结束:62.12 |  | |
| 12 | idle-右手握拳-idle | 开始:64.32结束:66.4 |  | |
| 13 | idle-右手掌心介绍-idle | 开始:70.4结束:73.28 |  | 右手掌心向上,从左往右划过 |
| 14 | idle-左手向前展示- idle | 开始:78.48结束:81.88 |  | 建议右手自然下垂 |
| 15 | idle-左手说话强调-idle | 开始:92.4结束:96.4 |  | 建议右手自然下垂 |
| 16 | idle-双手打开欢迎-idle | 开始:99.76结束:102.36 |  | 打开停留一会儿收起 |
| 17 | idle-双手打开着重-idle | 开始:107.68结束:114.4 |  | 双手着重轻微来回摆动强调 |
| 18 | idle-双手铺开- idle | 开始:116.84结束:121.8 |  | 模拟在数字人前面播放视频 请看屏幕下方展示的视频 |
# 3.3 动作编辑数字人验收标准
请严格按照以下项目自检,保证视频符合要求,不然会出现任务训练失败或者效果不好的情况:
标准数字人训练视频部分,请参考2.5小章节,必须先符合普通数字人采集验收标准;
动作编辑训练视频,每隔动作的起始动作和回归动作,每次都要和idel保证一致,务必准确回到原位置,不然影响实际效果
# 4. 多场景视频数字人物形象采集标准
多场景数字人的采集是在1章节要求上的额外要求。用于拍摄同一个人的多套服装/多个镜头,在同一个训练任务中同时进行提交。
# 4.1 多场景拍摄要求
多场景数字人的拍摄视频分为主视频和辅助视频。
主视频和辅助视频拍摄的共同要求如下:
- 同一个被拍摄人(妆容造型一致),同一个人不同妆容造型视为不同的被拍摄人。
- 人脸区域的灯光条件保持一致。例:主视频灯光和辅助视频灯光不一致,则不满足条件。
- 人脸角度需要保持一直。例:主视频和辅助视频都是正向面朝相机。若一个偏左,一个偏右,则不满足条件。
- 被拍摄人可以换不同的服装。
- 被拍摄人可以在屏幕中呈现不同的大小(如全身,半身)
- 被拍摄场景道具可以发生变化(如有桌子,没桌子,高脚椅,沙发等)

主视频拍摄要求:
- 无特殊要求,前30秒静默,后4分半说话,同2.1及2.2章节要求。
辅助视频拍摄要求如下:
- 不需要30秒静默。
- 开始拍摄直接开始说话及表演对应的肢体动作,总长度3-4分钟即可。
# 5. 使用PAAS平台生成数字人模型
# 5.1 生成人物形象训练任务
使用PAAS账号登录平台;
点击顶部"人物模型"—"人物模型生成",当前页面可以查看所有已经发起的任务状态(只限7天内的任务);
点击左侧"人物模型生成",进入任务生成模型页面;
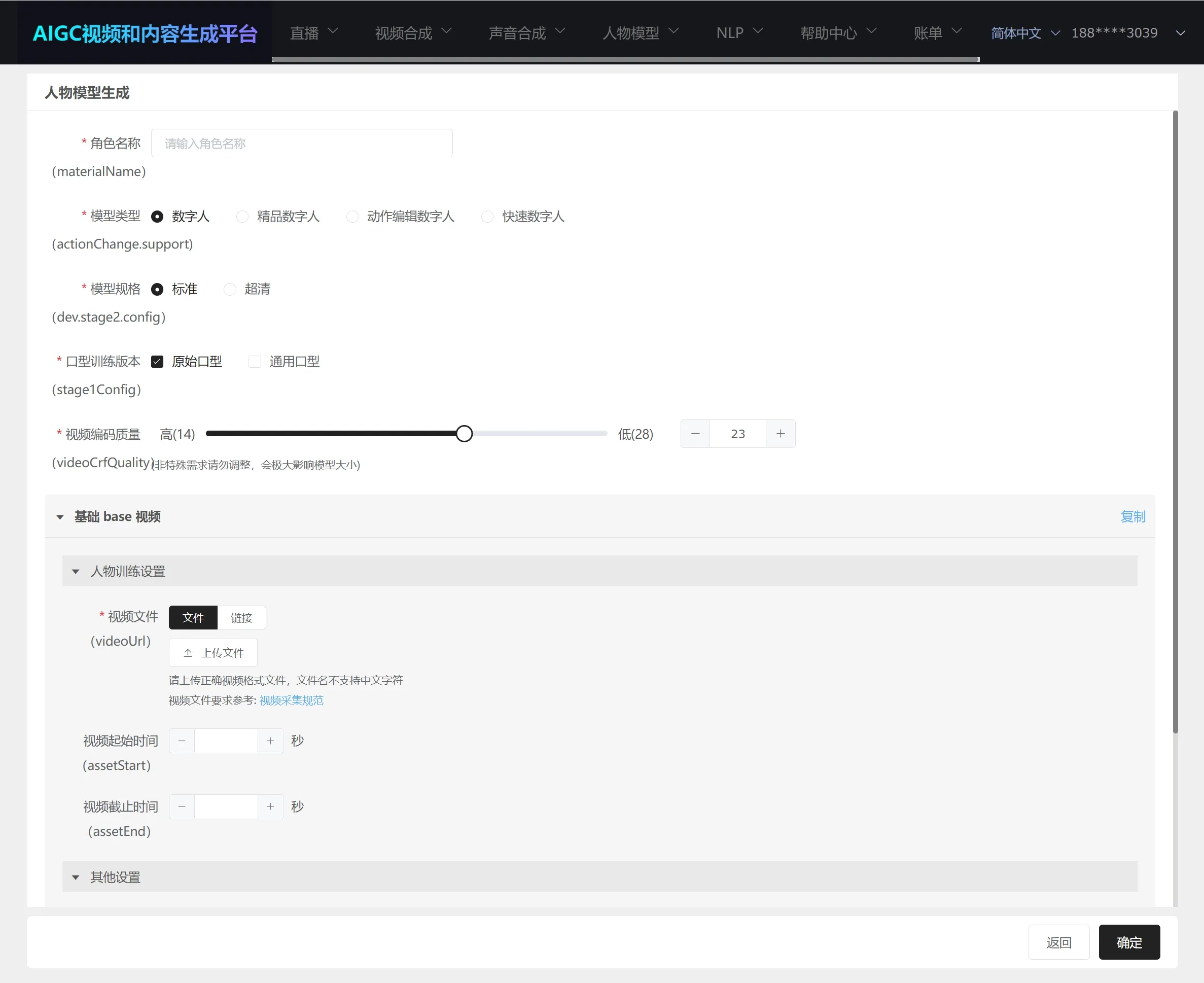
详细使用参数请见最后参数详解;
提交任务后,2k视频一般4-8小时会完成;
任务完成后,可以在"人物模型"—"人物模型生成"看到已完成任务,点击"更多",查看生 成好的人物形象数据信息;
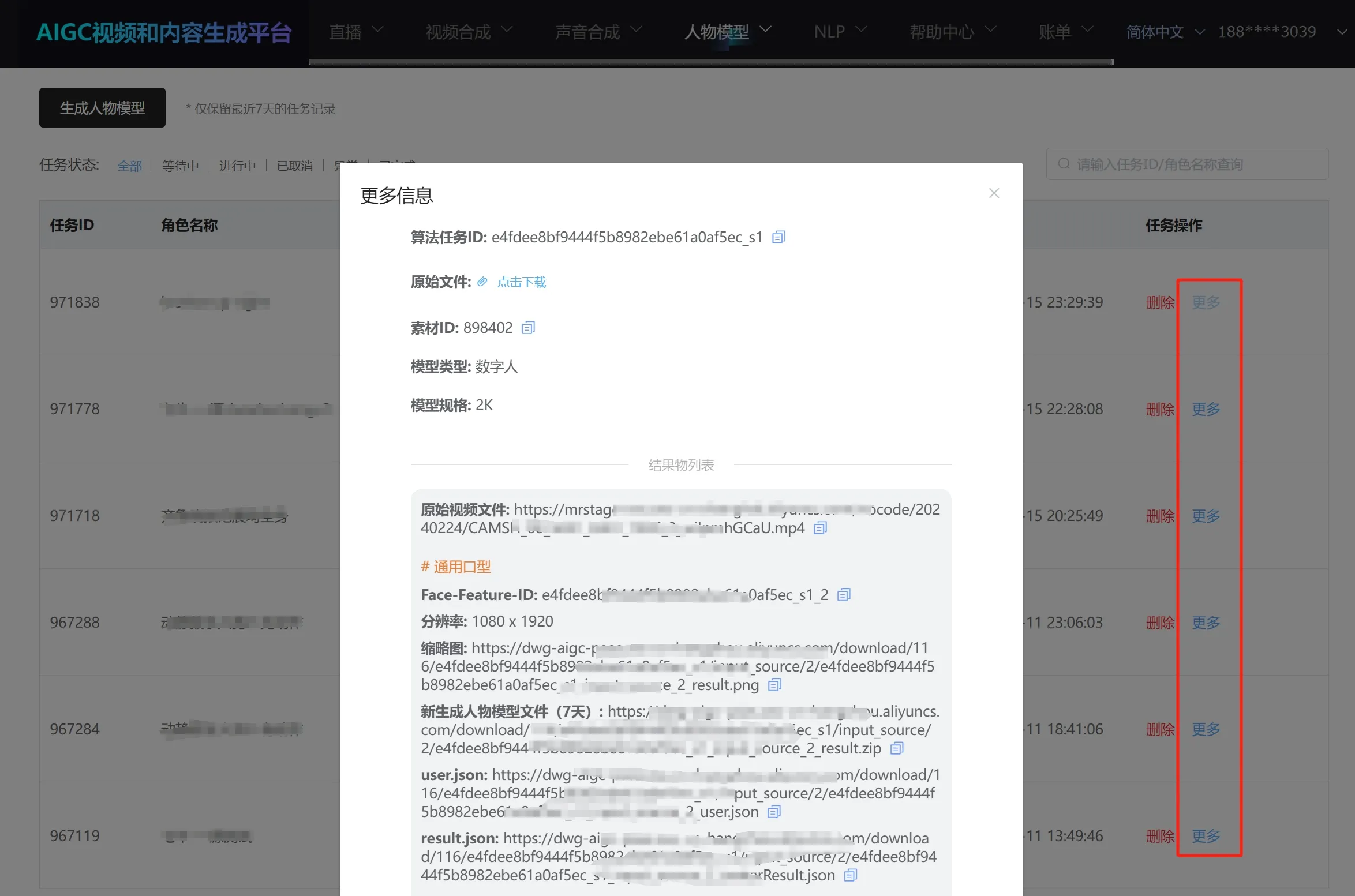
# 5.2 辅助视频/多场景视频人物形象训练任务
使用PAAS账号登录平台;
点击顶部"人物模型"—"人物模型生成",当前页面可以查看所有已经发起的任务状态(只限7天内的任务);
点击左侧"人物模型生成",进入任务生成模型页面;
先添加第一个视频,然后依次添加其他视频的具体信息;
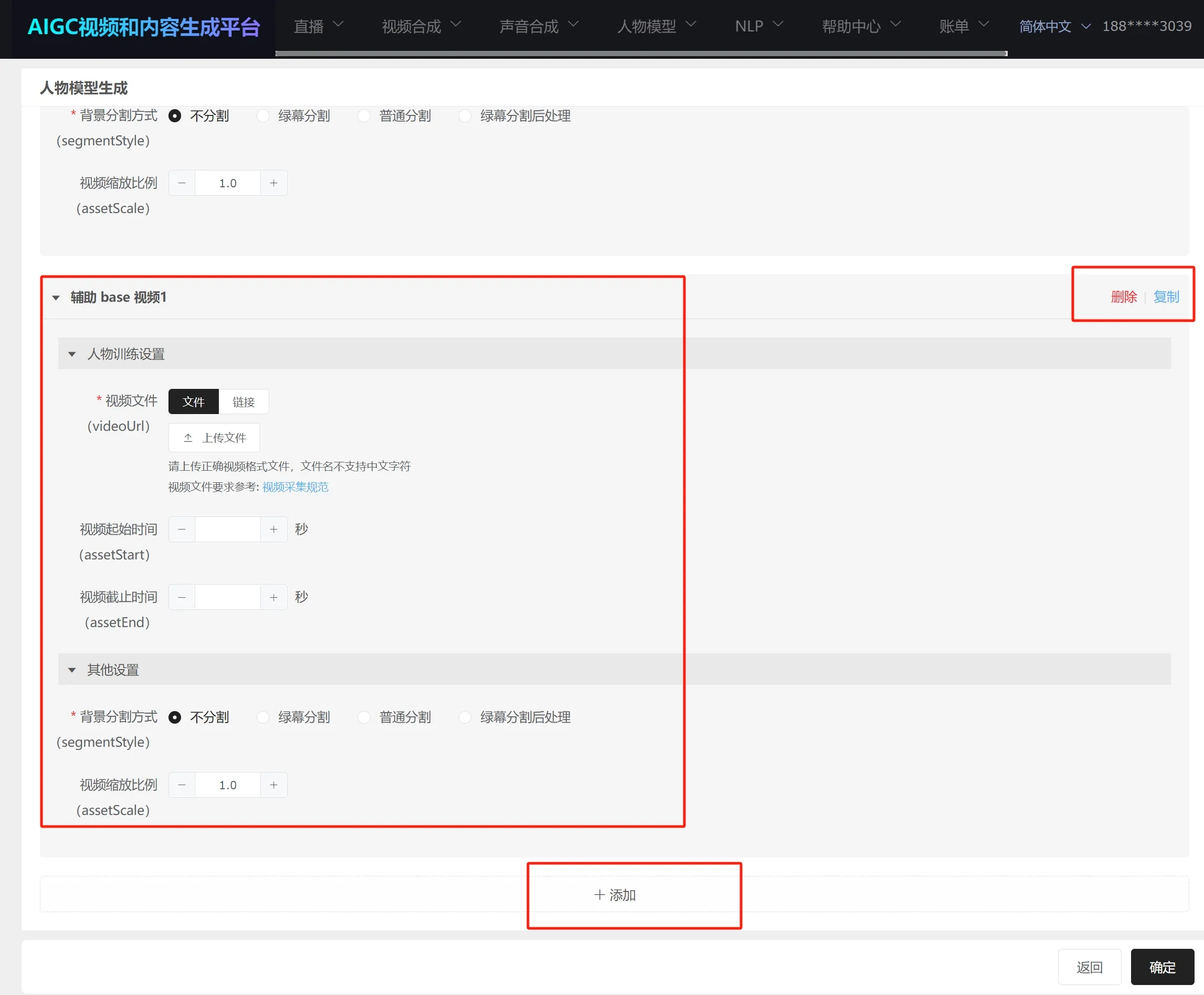
提交任务后,多视频训练时间一般较长,具体时间视视频个数而定;
任务完成后,可以在"人物模型"—"人物模型生成"看到已完成任务,点击"更多",查看生成好的人物形象数据信息;
# 5.3 参数详解
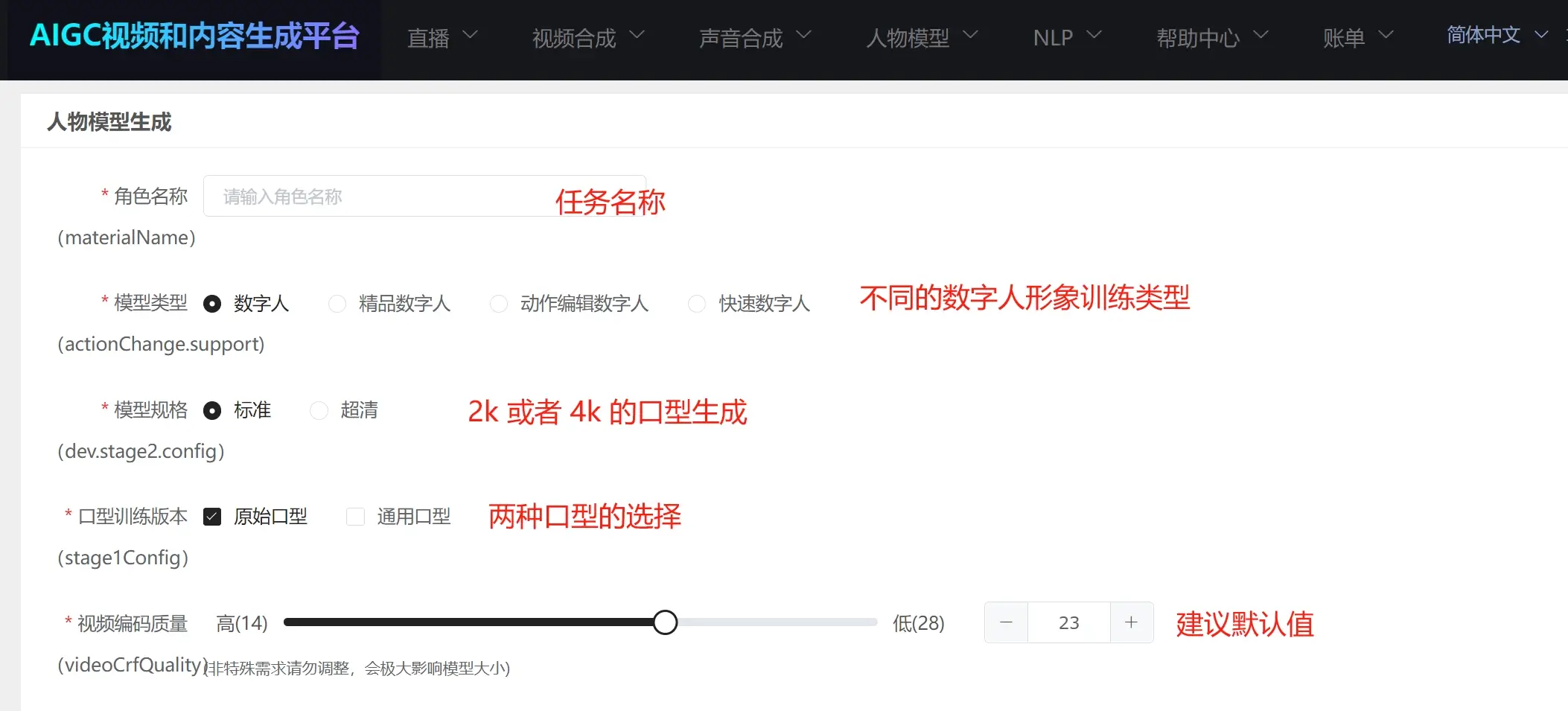
角色名称:即人物形象生成的任务名称;
模型类型:
数字人:普通数字人形象生成类型,可以支持绿幕分割、人像分割、不分割进行训练生成数字人;
精品数字人:支持静默状态的数字人,主要应用到直播互动,1v1问答,智能客服等场景中,需要按照具体要求拍摄才能进行当前类型的数字人形象生成训练,否则可能会出现效果不好的情况;
动作编辑数字人:支持触发指定动作的数字人(当前版本仅支持视频合成场景使用,直播场景还不支持触发指定动作的数字人进行直播),需要按照具体要求拍摄才能进行当前类型的数字人形象生成训练,否则可能会出现效果不好的情况;
快速数字人:实景数字人类型,无法使用绿幕分割、人像分割;
规格类型:"标准"即2K清晰度,"超清"即4K清晰度,请注意这个是口型生成的清晰度,不是视频的清晰度,视频清晰度取决于原始训练视频的分辨率; 通常状态下,如果是2K清晰度的原始训练视频,选择"标准",4K清晰度的原始训练视频,选择"超清";请注意选择超清训练时长也会延长;
口型训练版本:
原始口型:学习视频中人物的口型,并基于这个人的口型尝试生成口型;
通用口型:广义上大家认可方式尝试生成口型;一般情况下通用口型效果优于原始口型,建议都勾选,优先使用通用口型;
视频编码质量:建议使用默认值;
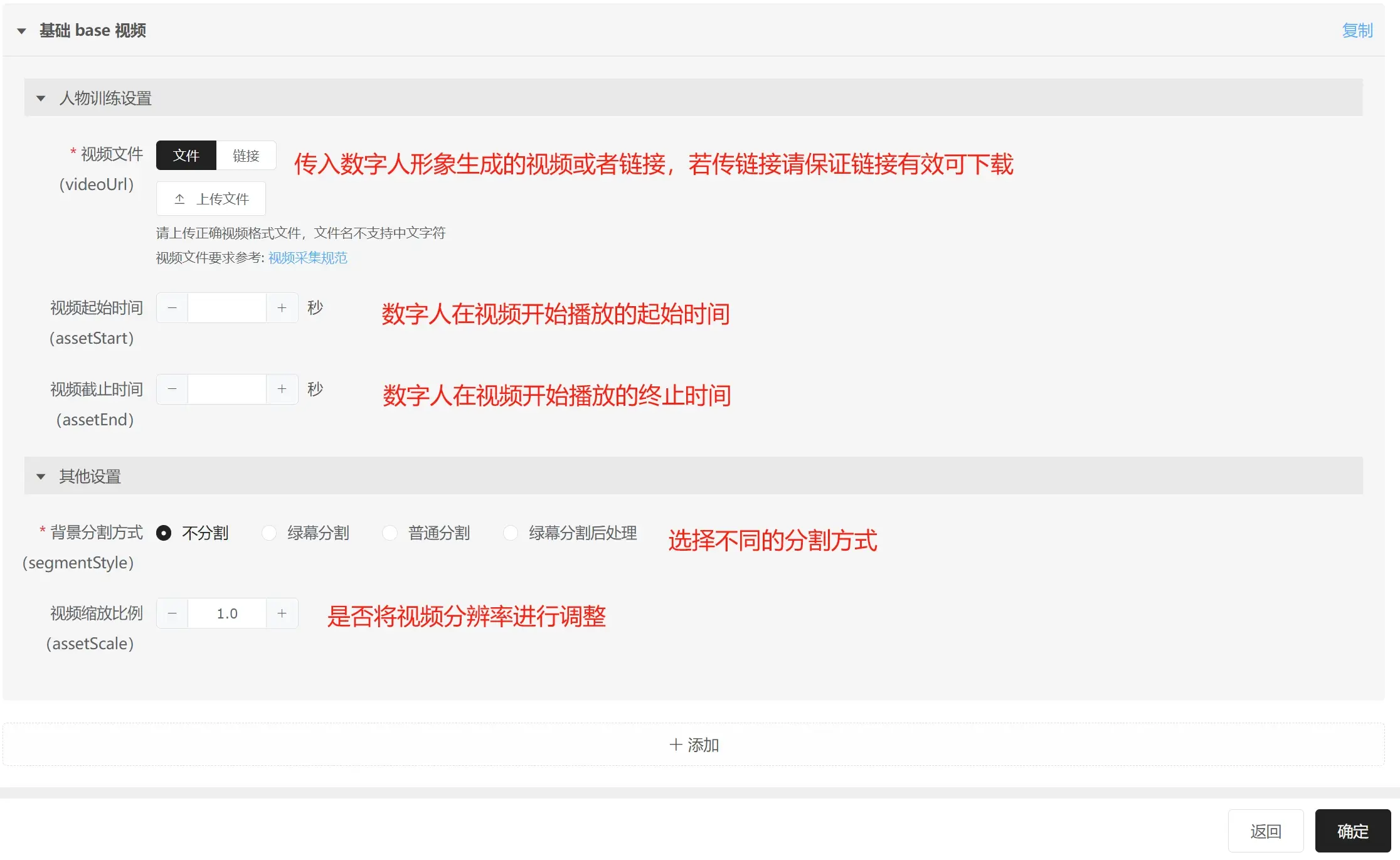
视频文件:可以传入本地文件,也可以传入文件的OSS链接;建议传入OSS链接,防止文件太大,上传失败;
视频起始时间:数字人在合成视频或者直播时播放的起始时间;(不填的话算法自动检索视频中人物开始动的起始时间)
视频截止时间:数字人在合成视频或者直播时播放终止的时间;(不填的话算法自动检索视频中人物开始动的起始时间的5分钟后的时间点,作为截止时间)
数字人合成视频或者直播时,只有口型部分,是根据文本或音频来生成的,其他所有表情、肢体动作,都是基于原视频播放的。播放的起始时间就是上面"视频起始时间"设置的时间,播放终止时间是上面"视频截止时间"设置的时间。播放逻辑是从"视频起始时间"第一帧开始播放,然后播放到"视频截止时间"最后一帧,然后倒序反向从"视频截止时间"最后一帧,播放到"视频起始时间"第一帧,然后重复循环此过程。
绿幕分割方式:
不分割:不使用分割,基于原视频的人物和背景进行训练;请注意此场景下无法更换背景图片;
绿幕分割:使用绿幕分割的方式进行分割,输出的数字人可以更换背景;
绿幕分割的原理是去绿,将视频中绿色的部分去除,所以使用绿幕分割需要注意不要有绿色、反绿、透绿的情况反发生,否则会将绿色扣掉,会出现一些错误的分割情况;
- 普通分割:使用人像分割的方式进行分割,输出的数字人可以更换背景;
人像分割的原理是把人物抠出来,因为人物可能有戴帽子、卷发、首饰、或者不同衣服与背景颜色接近等情况,整体效果无法完全可控,建议在无法使用绿幕分割的情况下,使用普通分割;
- 绿幕分割后处理:先进行人物形象生成,以及进行视频合成后,再尝试进行绿幕分割;一般情况下使用上面的"绿幕分割"就可以了,"绿幕分割后处理"适用于人脸扭动角度太大的情况,这样口型生成后再进行绿幕分割,唇部区域的绿幕分割效果会更好;
视频缩放比例:调整原始视频的分辨率,如果原视频是4K,后续输出的人物模型zip包比较大,又或者直播场景中想使用2K的人物形象,可以调整该参数;
绿幕分割相关参数:
平滑度:默认值即可
采样颜色:绿幕分割的颜色,默认都是绿色,也可以使用蓝色(RGB为0,0,255),不建议使用其他颜色进行分割,效果无法保证;
背景保留程度:抠图程度,如果想扣绿程度更多一些,可以将该值设置小一些(145,130,120,100,80,60等,不建议当前值太小,否则会损失边缘细节);
人物边缘保留宽度:人物边缘的扣绿程度,如果想扣绿程度更多一些,可以将该值设置小一些(30,20,10等,不建议当前值太小,否则会损失边缘细节);
去绿程度:建议默认值,如果有黄色衣服或者黄色元素,使用绿幕分割可能导致黄色便宜,可以将该值设置为1,保证黄色为原始黄色表达;
绿幕色彩平衡:建议默认值;
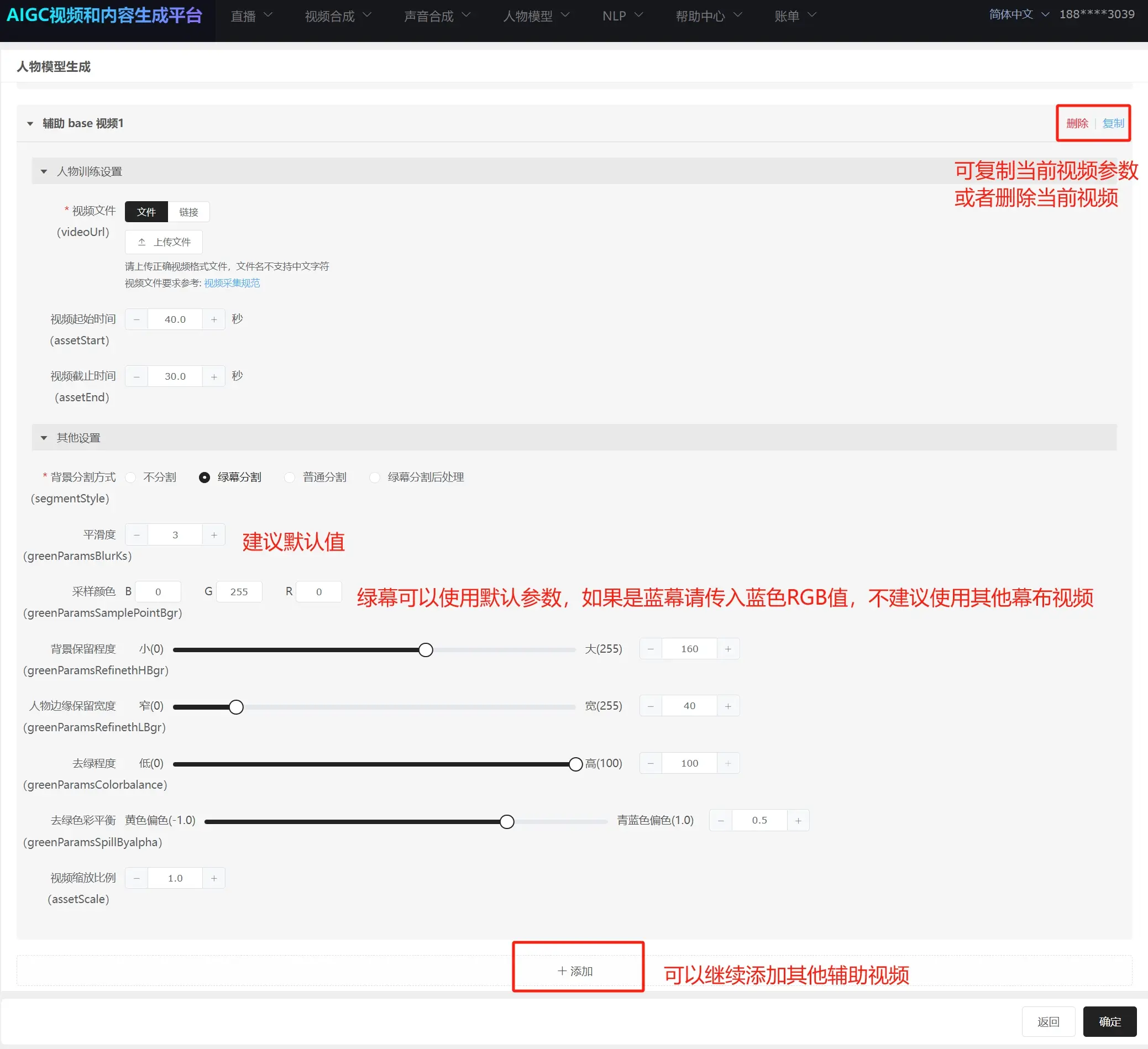
精品数字人相关参数:
静止部分开始时间:静默状态的开始时间,一般可以填写前面30s静默状态的起始时间;
静止部分结束时间:静默状态的结束时间,一般可以填写前面30s静默状态的结束时间;
动态部分开始时间:模特刚刚开始动起来的开始时间;
动态部分结束时间:模特最后不动结束时间(可以选择临近视频结束时某个动作的结尾时间);
过渡延迟:建议默认值;
过渡:建议默认值;
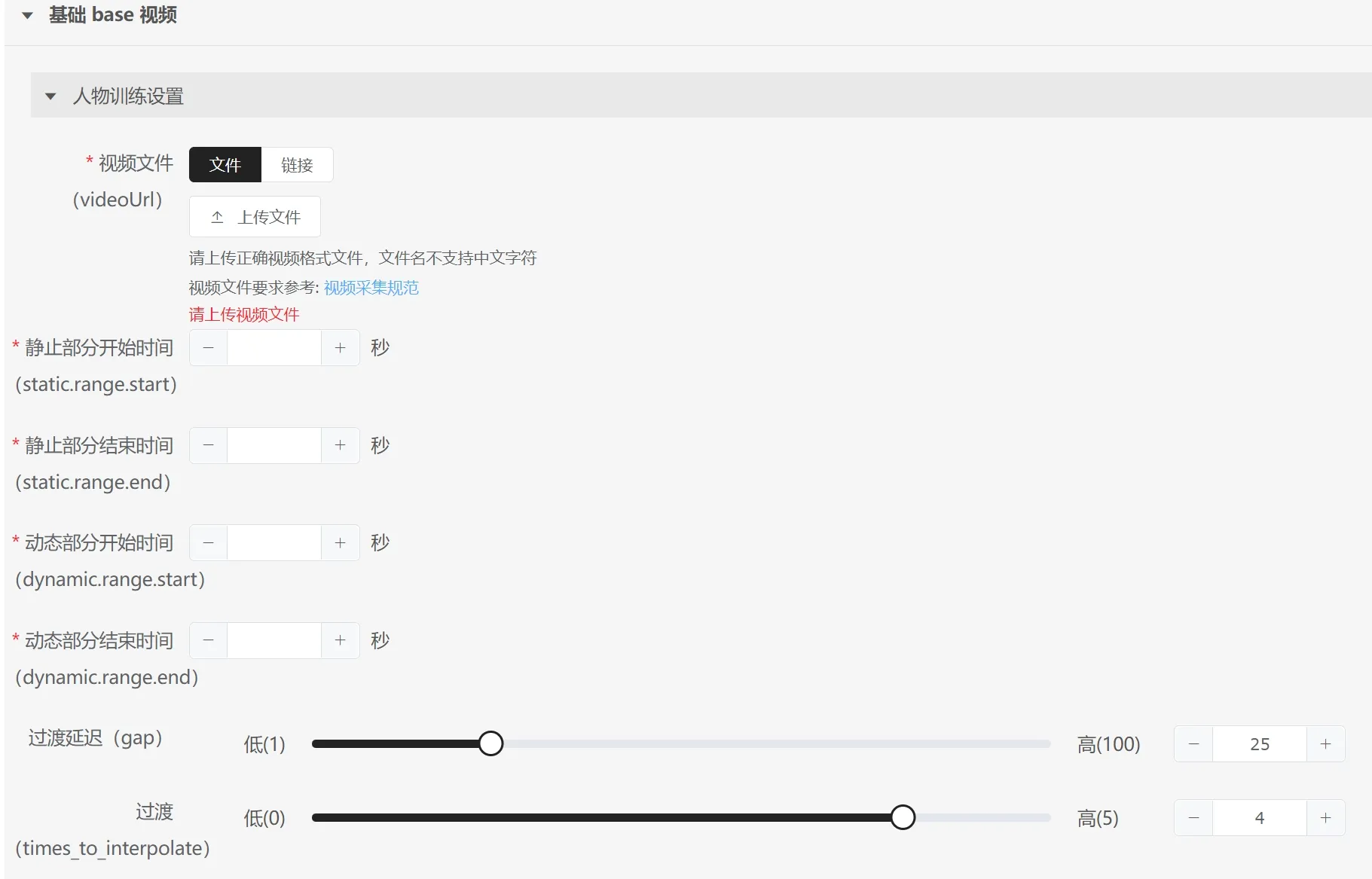
动作编辑数字人相关参数:
过渡延迟:建议默认值;
过渡:建议默认值;
动作1:动作1必须填idel时间段,本时间段是后续所有动作初始状态和终止状态,需要仔细挑选符合要求的时间段,建议找30s时间段即可;
动作名称:每个动作的命名,如第一个动作名字为"idel",动作2和后续动作需要填写视频中每个动作的名称;
开始时间:当前动作的起始时间;
结束时间:当前动作的结束时间;请注意为了更好的效果表达,最好具体到帧,如10s第十帧就是10.4秒(每秒25帧第十帧计算为0.4秒);
备注:可以不填
# 6. 使用PAAS平台更新数字人模型
# 6.1 使用流程
使用PAAS账号登录平台;
点击顶部"人物模型"—"人物模型更新",当前页面可以查看所有已经发起更新的任务状态(只限7天内的任务);
点击左侧"更新人物模型",进入任务生成模型页面;
填入需要更新的任务内容,右下角点击确定进行任务提交;
提交任务后,预计1-3小时完成任务;
任务完成后,可以在"人物模型"—"更新人物模型"看到已完成任务,点击"更多",查看生成好的人物形象数据信息;
# 6.2 注意事项:
原模型文件和原视频文件,必须是对应生成关系的一组数据,也就是这个模型文件必须是根据这个原视频文件输出的,不能填入无关的原视频文件和原模型文件;
数字人的口型信息不会更新,FFID信息使用之前人物训练生成的FFID信息;
模型类型:更新数字人模型时,仅限同类型更新,譬如无法将原普通数字人类型,更新为精品数字人或者动作编辑数字人,反之亦然;
视频起始时间和视频截止时间:可以进行修改;
背景分割方式:仅支持之前类型的背景分割方式下的更新,如若之前是绿幕分割,无法更新为普通分割;
背景分割参数:若之前为绿幕或者普通分割方式,可以更新对应的参数;
视频缩放比例:可以更新为不同的分辨率;如在视频合成场景需要一个4K分辨率的数字人,但是直播场景目前只能使用1080P分辨率才能保证不卡顿,可以通过人物形象更新,将视频播放比例输入0.5,即可输入1080P分辨率的数字人模型包;
# 7. 数字人采集相关注意事项
# 7.1 采集视频相关格式要求
- 格式要求为MP4,不能使用其他格式;尤其是MOV格式:iPhone录制的MOV格式,若打开了HDR,因iOS系统的HDR为闭源算法,所以无法完全还原MOV视频的色彩,请将MOV转为MP4再进行提交形象训练任务;
- 推荐1080P,支持4k;尽量不要使用其他分辨率,因为通用的分辨率可以适配更多的使用场景;
- FPS要求为25,若不是25,会将FPS强制转为25FPS;
- 推荐竖屏拍摄,也支持横屏(横屏训练输出默认是横屏格式的数字人);
# 7.2 视频内容声音画面要求
- 视频中不要出现外部声音,尤其不可出现第二个人的声音;尽量避免空调、服务器等设备噪音,避免场地其他噪音或环境震动;
- 绿幕拍摄的视频注意不要有任何反光的情况出现;如银首饰,亮面眼镜框,亮面腰带等;
- 注意打光,不要让人物的身上,或者非绿色物体有反绿的现象发生;如果出现反绿会很影响绿幕分割效果,后续会详细讲解提升绿幕效果的方式;
- 不可出现动态背景(视频、动画等) ;不可出现反光、透明、半透明材质的背景; 拍摄背景中不可出现直接的光源,比如采光窗户或发光的灯泡;
# 7.3 视频静默状态和口播状态检查
- 静默画面:整个采集流程前30 秒为静默画面采集,模特面向镜头保持嘴部闭合状态(可以模拟倾听的状态,可以有自然得体的轻微点头及微笑,但不宜过多;静默30秒需始终保持嘴唇闭合状态);
- 口播画面:静默画面拍摄够30 秒后,保持光照环境不变,保持模特pose 不变,进入口播画面采集阶段;
- 在口播画面采集阶段,口播稿内容、模特语速、情绪、表情、手势都尽量模拟将来数字人要应用的典型场景(比如将来数字人主要用于旅游产品直播售卖,那么直接使用旅游产品直播稿,直播卖货的语速、情绪、表情、手势来完成采集,尽量模拟真实的使用场景)
# 7.4 形象训练任务可能失败的点
人脸缺失:确保每一帧不能有人脸丢失,不要手或者物品遮挡人脸已经唇部;
多人脸:确保每一帧都不能有两张人脸(譬如海报中的人脸入境可能会导致失败);
大角度人脸:人脸角度建议30°以内,大角度(45°或更多)支持识别,但是有一定概率会失败。大角度走动示例视频 (opens new window)
非连续帧:不连续的帧如果保证每帧都有人脸不会失败,但是训练后的结果会出现跳帧情况;如果非连续帧出现人脸缺失会导致任务失败;
视频其他要求说明:
- 拍摄时模特可以化妆,输出数字人效果也会有美妆;当然也可以使用我们的后期美妆特效;
- 过于宽松的发型,可能会影响绿幕分割效果(不考虑绿幕请忽略这点);
- 避免有吊坠的耳饰或其他饰物 ,可能有反光;
- 避免发型或过大的眼镜遮挡模特下半脸 ,数字人仅仅是口型生成,唇部周边区域如果有眼镜框可能导致口型生成错误;
- 避免反光过强的唇彩或眼影可能会影响绿幕分割效果,唇部生成效果;
# 8. 如影声音复刻采集标准
尊敬的客户,为了能帮助您获得高质量的录音文件,我们特意为您准备了一份录音指南。请参照以下步骤进行录音,以获得最佳的 TTS 声音复刻效果。
# 8.1 环境准备
- 请在一个安静的小房间里进行录音(远离交通噪音、人群喧哗和其他干扰声源的地点),录音棚是最好的选择。请避免在户外、空旷的办公室或有明显噪音、回声的场所进行录制。
- 请确保只有一个人在录音过程中发言,避免录入其他人的声音。
# 8.2 设备准备
- 我们建议您使用品质较好的麦克风,如 Sennheiser、AKG 等品牌的产品。您也可以选择使用较新的头戴式会议耳麦。如果条件有限,使用新款 iPhone 的机身麦克风也是可以的,但请避免使用 AirPods 等蓝牙耳机。
- 在录音过程中,请确保您始终处于麦克风的推荐收音范围内,并尽可能保持一致的距离。
# 8.3 发音要求
- 注意不要重复的文档来回读,文稿只读一次;
- 录制的时候尽可能保持同一个语速、语调、感情状态;发音准确清晰,发音音色音调与期望克隆的音色一致;
- 音量适中,避免离话筒过近产生的爆音,杂音,以及过远声音过小;
- 避免呼吸声,吸气声,句首句尾句中无意义的“嗯”“啊”等口语,避免杂音;
- 音频格式尽可能是无损音频;
- 必须做好降噪,保证音频无环境噪音(否则克隆的音色会有杂音)。
# 8.4 声音复刻注意事项
- 建议录制至少20分钟的有效音频,推荐录制30分钟,更长时间对声音完全复刻还原会更有帮助。
- 对于较长的录制,可以分段进行,即中间休息一段时间,但所有录制的音频请保持一致的语速、音量、音高和音调。
- 需要一段声音授权音频文件,文件要求详见附录。
- 如果是大模型声音复刻,建议录制50-90秒的有效音频。
# 8.5 格式要求
- 声音复刻音频文件和授权音频文件素材支持格式:wav、mp3、m4a、mp4、mov、aac。
# 8.6 附录
用户授权音频文件主要是用来确认用户已经授权给我方进行声音复刻,音频内容必须按照指定文案发音进行录制。
- 以下为中文示例:
xx(发音人姓名)确认我的声音将会被xx(公司名称)使用于创建合成版本语音。
授权文件支持其他语言,具体如下:
- 英文:
I [state your first and last name] am aware that recordings of my voice will be used by [state the name of the company] to create and use a synthetic version of my voice.
- 日语:
私(姓名を記入)は自身の音声を(会社名を記入)が使用し、合成音声を作り使用されることに同意します。
- 韩语:
나는 [본인의 이름을 말씀하세요] 내 목소리의 녹음을 이용해 합성 버전을 만들어 사용된다는 것을 [회사 이름을 말씀하세요]알고 있습니다.
# 9. 使用PAAS平台进行声音复刻
- 使用PAAS账号登录平台;
- 点击顶部"声音合成"—"TTS个人音色模型生成-Qid(推荐)"—"点击生成";

- 填入任务信息,并上传对应的音频文件;

- 点击"确定"即可创建音色复刻任务;

- 任务完成后,点击"更多"可以下载结果文件;

- 结果文件中有对应的音色qid等信息,请留存以供请求使用。
以TTS6输出结果为例,结果文件示例如下:
{
"msg": "task is finished",
"stage": "deployment",
"voice": {
"qid": "eQz_IP:AEAyxxxxxxxxRSUpItdQ0szE10LCzSU3QtDS0tjVLMDMK",
"name": "-tts6",
"gender": 1,
"languages": [
"en-US",
"zh-CN",
"af-ZA",
"am-ET",
"de-AT",
"de-CH",
"de-DE",
"el-GR",
"en-AU",
"en-CA",
"en-GB",
"en-IE",
"en-IN",
"fr-BE",
"zh-HK",
"zh-TW",
"zu-ZA"
]
},
"taskId": "tts6-051370ad-96cd-43a4-8a42-8fcdfa8658e6",
"tenant": "116",
"modelUrl": "",
"taskType": "TTS6",
"taskStatus": 5,
"stageStatus": 5,
"updatedTime": "2024-06-25T13:11:10.000194872Z",
"sampleAudioUrl": ""
}
# 10. 如影声音复刻相关注意事项
- TTS3 音色克隆时间约20小时左右;
- TTS6 音色克隆时间预计1小时以内;
- 声音复刻音频录制的时长请确保按照对应要求来,TTS3 不少于20分钟,推荐30分钟;TTS6 建议1分钟,不要超过90秒;
- 授权音频请严格按照对应文案来发音,并且要求与声音复刻音频为同一个人;
- 所有声音录制都要求降噪,有环境噪音复刻的TTS效果会与本人音色出现非常大的差异;
- TTS3 仅复刻中文音色;TTS6 可以复刻中文、英文等多国语言音色,但是声音还原度不如TTS3;
← 欢迎访问 通用数据结构及平台规范 →