# Shadow Digital Human/Shadow Voice Replication Collection Standards
For human collection, it’s recommended to primarily read Chapters 1, 5, 6, and 7.
# 1. Rapid Digital Human/Common Digital Human Collection Standards
# 1.1 Shooting Environment & Equipment
# 1.1.1 Shooting Environment Requirements
- Quiet environment: No external sound interference during shooting, including other people's voices, sounds of air conditioners, fans, or other electrical noises, as well as other noises or vibrations.
- Clean shooting background:
- No dynamic backgrounds (videos, animations, etc.)
- No reflective, transparent, or semi-transparent backgrounds
- No direct light sources in the shooting background, such as windows with direct sunlight or glowing bulbs
- Green screen shooting is recommended (background of digital human video can be changed)
- Configure appropriate lighting based on shooting quality requirements to ensure overall even illumination and no significant shadows in the background environment.

# 1.1.2 Shooting Equipment Requirements
- Use a DSLR camera or camcorder capable of shooting in 1080P resolution or higher (vertical shooting with 1080*1920 resolution is recommended).
- Configure a microphone that can be connected to the DSLR camera (or camcorder). Do not clip the microphone on the model; it is recommended to place it as close to the model as possible but outside the camera frame. Confirm in advance that the collected sound is clear and free from background noise.
- Using a teleprompter is recommended (or use an iPad with a teleprompting app).
# 1.1.3 Model Appearance and Props Preparation
- Clean the face before shooting (men should trim facial hair) and apply appropriate makeup based on the need.
- Overall makeup, clothing, and props should aim for the desired effect of the final digital human but avoid the following:
- Avoid overly loose hairstyles
- Avoid dangling earrings or other jewelry
- Avoid hairstyles or large glasses that cover the lower part of the face
- Avoid overly reflective lip gloss or eyeshadow
# 1.2 Shooting Process
# 1.2.1 Collection Process
- The overall collection process is divided into two parts: silent frames and talking frames.
- Silent frames: The first 30 seconds of the entire process are for silent frame collection. The model faces the camera with mouth closed (can simulate a listening state with natural, appropriate slight nodding and smiling; lips should remain closed for the entire 30 seconds).
- Talking frames: After shooting 30 seconds of silent frames, without changing the lighting or pose, proceed to the talking frames collection stage (5 minutes of talking frames are sufficient for digital human collection for short video production; for live streaming digital humans, extend the talking frames appropriately, recommending 20-30 minutes).
- During the talking frames collection, the content, speech speed, emotions, expressions, and gestures of the model should simulat typical scenarios for the future digital human (e.g., if the digital human is primarily used for live streaming to sell tourism products, directly use the live streaming script, speed, emotions, expressions, and gestures to complete the collection, simulating a real use scenario as closely as possible).
# 1.2.2 Collection Process Tips
- Environment:
- Maintain a quiet site during collection, no external sound interference during shooting, especially without a second person's voice; minimize noise from air conditioners, servers, etc., and avoid other noise or ambient vibrations.
- Equipment:
- Recommended resolution of 1080*1920, 25fps, vertical shooting.
- Use a microphone connected to the camera to simultaneously record the on-site sound, ensuring collected sound is clear and free from background noise.
- Model:
- After makeup is ready, position the model appropriately (either sitting or standing as required by the shoot).
- When using a green screen, ensure the model is at least 2 meters away from the green screen to avoid green spill (which will cause poor keying effects in post-production).
- Ensure the model's face is evenly lit with no strong shadows (especially under the nose, sides of the nose, and neck).

- Ensure the model is in the correct position in the frame and that their body or hands do not go out of the frame during gestures.

- During shooting, the model should look straight at the camera, avoiding large angles of looking up, down, sideways, or away from the camera.

- The model should speak clearly with full mouth shapes. When pausing, the mouth should be closed without gaps; avoid situations where the mouth is open but no sound is made.
- Even when taking breaks between sentences, ensure the lips are closed without gaps.
- The teleprompter text does not need to be read strictly word for word. As long as the appropriate emotion and expression are maintained, the model is allowed to adapt the script naturally while speaking.
- If the model makes a mistake, pauses, or encounters an unforeseen incident, they should close their mouth completely for 2-3 seconds before continuing (but avoid laughing, coughing, clearing the throat, or making any irrelevant sounds).
- The model can use natural body language, but avoid large body movements, particularly of the shoulders and neck.
- Adding some gestures can make the generated model look more natural, but ensure the gestures do not cover the face.
- Throughout the collection process, keep the model's body and gestures within the video frame.
- During the entire talking frame collection, mimic the desired digital human scenario with matching expressions and emotions. For example, if the digital human will be used for live streaming sales, record with the emotions and state of a live streaming saleshost.
# 1.2.3 Note on Using Mobile Phones for Collection
- When using an iPhone for shooting, try to disable HDR. The HDR algorithm of the iPhone is not open-source, making it difficult to perfectly replicate HDR colors in the video.
- iPhone outputs in mov format, convert to mp4 format and confirm the overall video effect before uploading for model generation training.
# 1.2.4 Green Screen Collection Tips
The principle of green screen separation is to eliminate green, removing the green parts from the video. Thus, avoid any green, reflective green, or transparent green situations as these will be removed, leading to incorrect separations.
- Ensure only one shade of green for the green screen. Multiple shades affect the separation effect.
- Ensure the lighting is adequate to make the green screen area entirely green, with no green in the non-green screen areas. Avoid any reflective green or transparent green phenomena.
- Make sure the model or non-green screen areas are not reflective or transparent as it might reflect green, affecting the separation effect.
If unsure about the green screen effect before or during shooting, refer to the next chapter "Preview Green Screen Effect in Advance" and shoot a short video to confirm the green screen effect.
# Common Green Screen Issues and Incorrect Examples:
- Ensure the green screen area is purely green. The image below has black objects and spots at the top-left corner and top of the head.

- Ensure the green screen area is purely green. The image below shows non-green areas at the top and bottom.

- There are green shadows in the gaps of the skirt, which will affect results. Avoid areas that might create shadows.

- There are green shadows in the gaps of the skirt, which will affect results. Avoid areas that might create shadows.

- Due to lighting effects, there might be black shadows in the middle of the shoes, which need to be avoided. Otherwise, there will be issues in the black-green separation.

- Avoid reflective green. Reflective green will result in poor green screen effects. In the image below, the clothes reflect strong light onto the green screen, causing the body to appear green, making it difficult to get a good separation effect.

- Avoid transparent objects. In the image below, the spectacle lenses have green transparency. The shiny phone case reflects green, both causing separation errors.

- Avoid reflective green. In the image below, the
# 1.3.3 Green Screen Parameters and Application in Digital Human Model Training
When creating a task or after task completion, there is a "One-click Copy Parameters" option. The specific parameter definitions are as follows:
{
"greenParamsRefinethHBgr": 160, // Background retention level
"greenParamsRefinethLBgr": 40, // Edge width retention level for characters
"greenParamsBlurKs": 3, // Smoothness
"greenParamsColorbalance": 100, // Degree of green removal
"greenParamsSpillByalpha": 0.5, // Green color balance removal
"greenParamsSamplePointBgr": [ // Sample color
0,
255,
0
],
"greenParamsSampleBackground": { // Background color
"color": [
255,
0,
0
]
}
}
These parameters can be used when training or updating the character model.
# 1.3.4 Confirming Green Screen Effects on Mobile
For a quick and rough on-site effect confirmation, you can use our mobile green screen effect confirmation software. However, the final effect should be confirmed based on the results from our platform.
The usage process is as follows:
- Contact our business or after-sales colleagues to apply for a trial of our Effects Demo.
- Download and install the Effects Demo, go to the homepage and click "Effects."
- Select the "Segmentation" item.
- Switch to the rear camera and point it at the green screen environment.
- Click green screen segmentation to confirm the effect. There are 3 default background images, or you can use a photo from your phone as the background image to confirm the effect.

# 2. Premium Digital Human Collection Standards
# 2.1 Shooting and Collection Requirements
Model-related:
- The total length of the collected video is around 5 minutes, with no changes.
- The model's actions during the collection process consist of two parts: 30 seconds of static footage followed by around 4 and a half minutes of talking footage. No changes.
- Set the body posture in the static part as the default posture. The entire static part is mainly shot with the default posture, simulating a listening state with light nods and smiles, but avoiding excess movement. Lips must remain closed for the full 30 seconds of silence.
Static footage example:


- The start of the talking footage requires the model to begin in the default posture. After performing some body and arm movements, the model should return to the default posture (same body posture, arm position, hand actions). Generally, transitioning from default posture -> action -> return to default posture should be controlled within 10 seconds. After returning to the default posture, the next action can begin, repeating this cycle, continuously returning to the default posture after completing each action.
- Actions for entering the talking footage:

- Actions within the talking footage (Example 1):

- Return to default posture:

- Actions within the talking footage (Example 2):

- Return to default posture:

# 2.2 Premium Digital Human Acceptance Criteria
Please strictly self-check according to the following items to ensure that the video meets the requirements; otherwise, tasks may fail in training or yield poor results:
- Please refer to section 2.5, the standard criteria for ordinary digital human collection must be met first.
- Each time returning to the default posture, the silence posture must be consistent. Be sure to return accurately to the original position.
# 3. Action Editing Digital Human Collection Standards
# 3.1 Video Requirements
The action editing digital human video requires the output of two parts:
- Standard digital human training video: used for lip sync training, requiring a length of 3 and a half minutes, 30 seconds of silence with lips closed at the beginning, and 3 minutes of talking.
- Action editing training video: used for different action editing training, with strict requirements. Please ensure to shoot according to the requirements below to avoid unsatisfactory results. Action Editing Sample Video (opens new window)
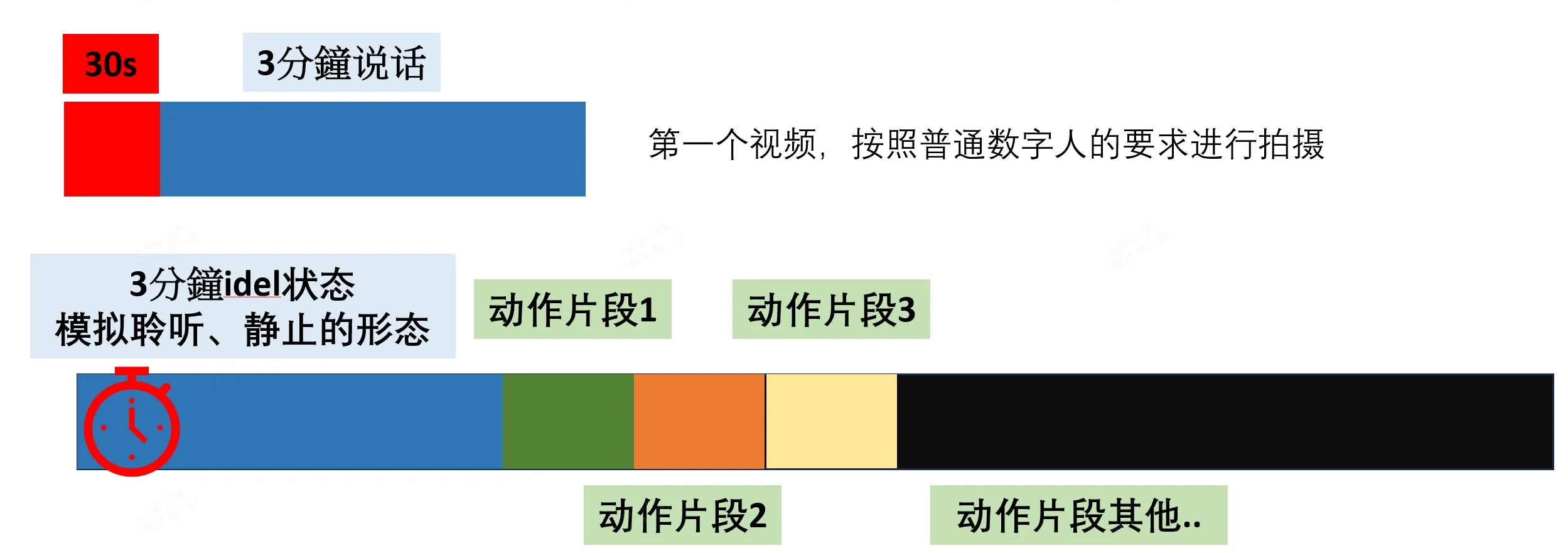
# 3.2 Shooting Requirements
- The standard digital human training video part is used for lip sync training, with the same shooting method as ordinary digital human videos.
- The character posture, camera status, and scene in the standard digital human training video must be consistent with the action editing training video.
- The action editing training video includes idle actions, ordinary actions 1, ordinary actions 2, ordinary actions 3, ordinary actions 4, ordinary actions N, etc. Each action's start and end must be completely consistent with the idle action. This is crucial because if the actions do not return to the idle state after completion, errors will appear during action editing display. High consistency is required from the shooting model.
- It is recommended that idle actions be no longer than 3 minutes, and other actions be within 10 seconds, ideally around 3 seconds. Specific cases are detailed in the operational guide.
- Environmental noise is not restricted for the action editing training video, and background noise is acceptable since only the action video content will be used.
- Idle action and subsequent different actions can be shot separately, but ultimately need to be combined into one video for submission.
Due to the high difficulty of shooting, it is recommended to prepare the shooting script in advance, communicate with the model beforehand, and rehearse. Sample script as follows:
| Shooting Content | Time | Reference Effect | ||
|---|---|---|---|---|
| 1 | Basic lip sync shooting | 5 minutes 30 seconds | Standard as in previous versions | |
| 2 | Idle static action | Start: 35.4 End: 37.32 |  | Head should move naturally to simulate listening to others |
| 3 | Idle - Right hand wave - Idle | Start: 8.5 End: 11.4 |  | |
| 4 | Idle - Right hand show - Idle | Start: 26.64 End: 29.32 |  | |
| 5 | Idle - Right hand emphasis - Idle | Start: 19.4 End: 23.92 |  | |
| 6 | Idle - Right hand forward - Idle | Start: 14.88 End: 17.92 |  | |
| 7 | Idle - Right hand up - Idle | Start: 32.52 End: 35.48 |  | |
| 8 | Idle - Right finger emphasis - Idle | Start: 37.48 End: 43 |  | |
| 9 | Idle - Right hand thumbs up - Idle | Start: 47.12 End: 49.56 |  | |
| 10 | Idle - Right hand OK - Idle | Start: 53.56 End: 55.72 |  | |
| 11 | Idle - Right hand heart - Idle | Start: 59.8 End: 62.12 |  | |
| 12 | Idle - Right hand fist - Idle | Start: 64.32 End: 66.4 |  | |
| 13 | Idle - Right hand introduction - Idle | Start: 70.4 End: 73.28 |  | Palm facing up, sweeping from left to right |
| 14 | Idle - Left hand forward - Idle | Start: 78.48 End: 81.88 |  | Recommended to let the right hand naturally hang down |
| 15 | Idle - Left hand emphasis - Idle | Start: 92.4 End: 96.4 |  | Recommended to let the right hand naturally hang down |
| 16 | Idle - Both hands open welcome - Idle | Start: 99.76 End: 102.36 |  | Open and pause for a moment |
| 17 | Idle - Both hands open emphasis - Idle | Start: 107.68 End: 114.4 |  | Slight back and forth swing for emphasis |
| 18 | Idle - Both hands spread - Idle | Start: 116.84 End: 121.8 |  | Simulate video playback in front of digital human, directing towards the screen below |
# 3.3 Action Editing Digital Human Acceptance Criteria
Please strictly follow the self-inspection items below to ensure the video meets the requirements; otherwise, task training may fail or have poor results:
- For standard digital human training videos, refer to section 2.5. You must first meet the general digital human collection and acceptance standards.
- In action editing training videos, the initial and return actions of each movement must be consistent with the idle state and must accurately return to the original position, or it will affect the actual results.
# 4. Multi-Scene Video Digital Human Image Collection Standards
The collection of digital humans in multi-scene videos imposes additional requirements over those in section 1. This is for shooting multiple outfits or multiple shots of the same person, to be submitted in a single training task.
# 4.1 Multi-Scene Shooting Requirements
Multi-scene digital human shooting videos are divided into main videos and auxiliary videos.
The common requirements for shooting main and auxiliary videos are as follows:
- The same person (makeup and styling remain consistent); different makeup and styling are considered different individuals.
- Lighting conditions for the facial area must remain consistent. Example: If the lighting in the main video is different from the auxiliary video, the condition is not met.
- The face angle must remain consistent. Example: Both main and auxiliary videos must face the camera. If one faces left and the other right, the condition is not met.
- The subject can change outfits.
- The subject can appear in different sizes on the screen (e.g., full body, half body).
- Props in the shooting scene can vary (e.g., with or without a table, a high chair, a sofa, etc.).

Main video shooting requirements:
- No special requirements; the first 30 seconds should be silent, followed by 4 and a half minutes of talking, according to the requirements in sections 2.1 and 2.2.
Auxiliary video shooting requirements are as follows:
- No need for 30 seconds of silence.
- Start talking and performing corresponding body movements immediately upon shooting; the total length should be 3-4 minutes.
# 5. Using the PAAS Platform to Generate Digital Human Models
# 5.1 Generating Character Image Training Tasks
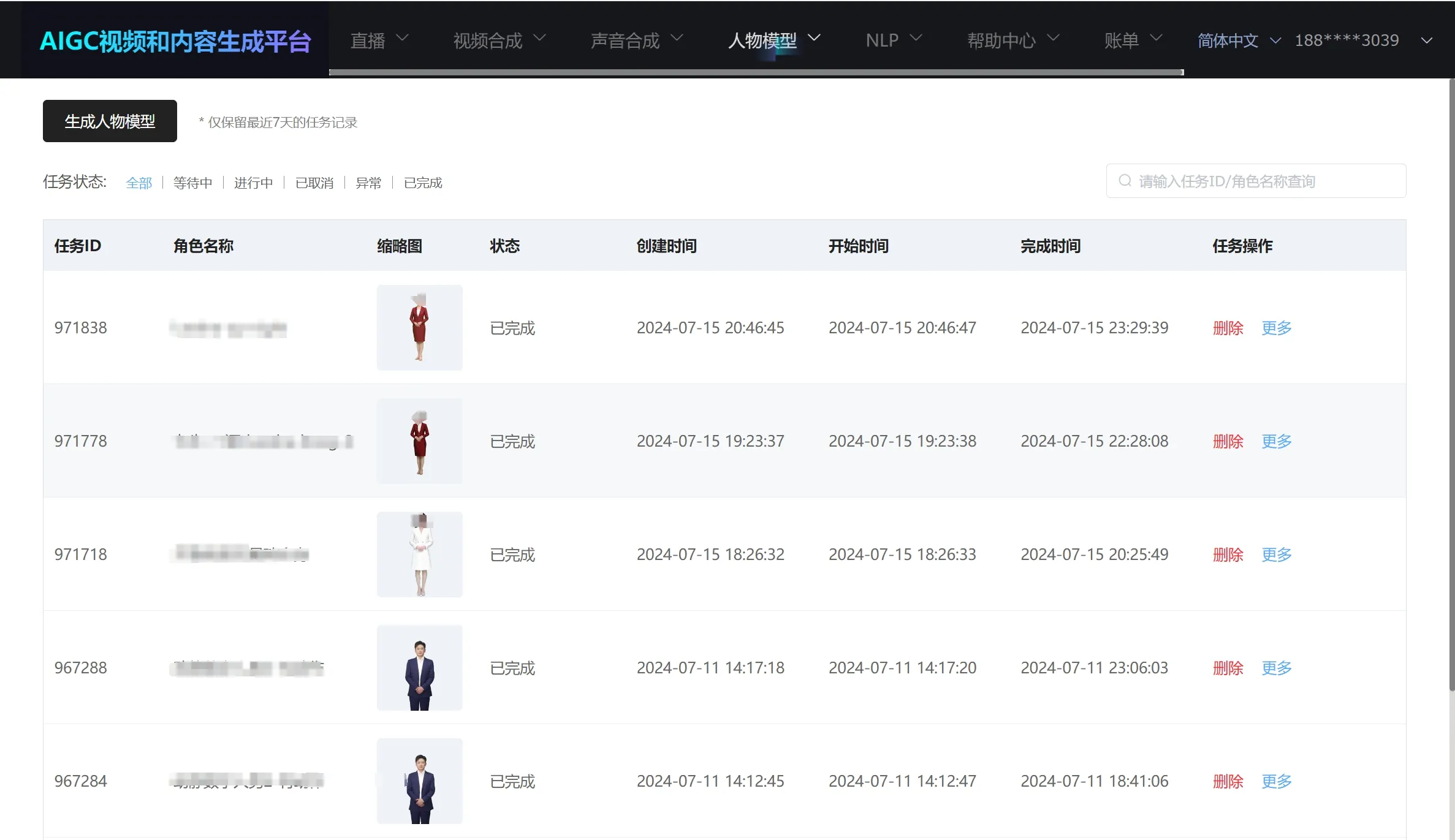
- Log in to the platform using a PAAS account.
- Click on "Character Model"—"Character Model Generation" at the top. The current page can view the status of all initiated tasks (limited to tasks within the last 7 days).
- Click on "Character Model Generation" on the left to go to the task model generation page.
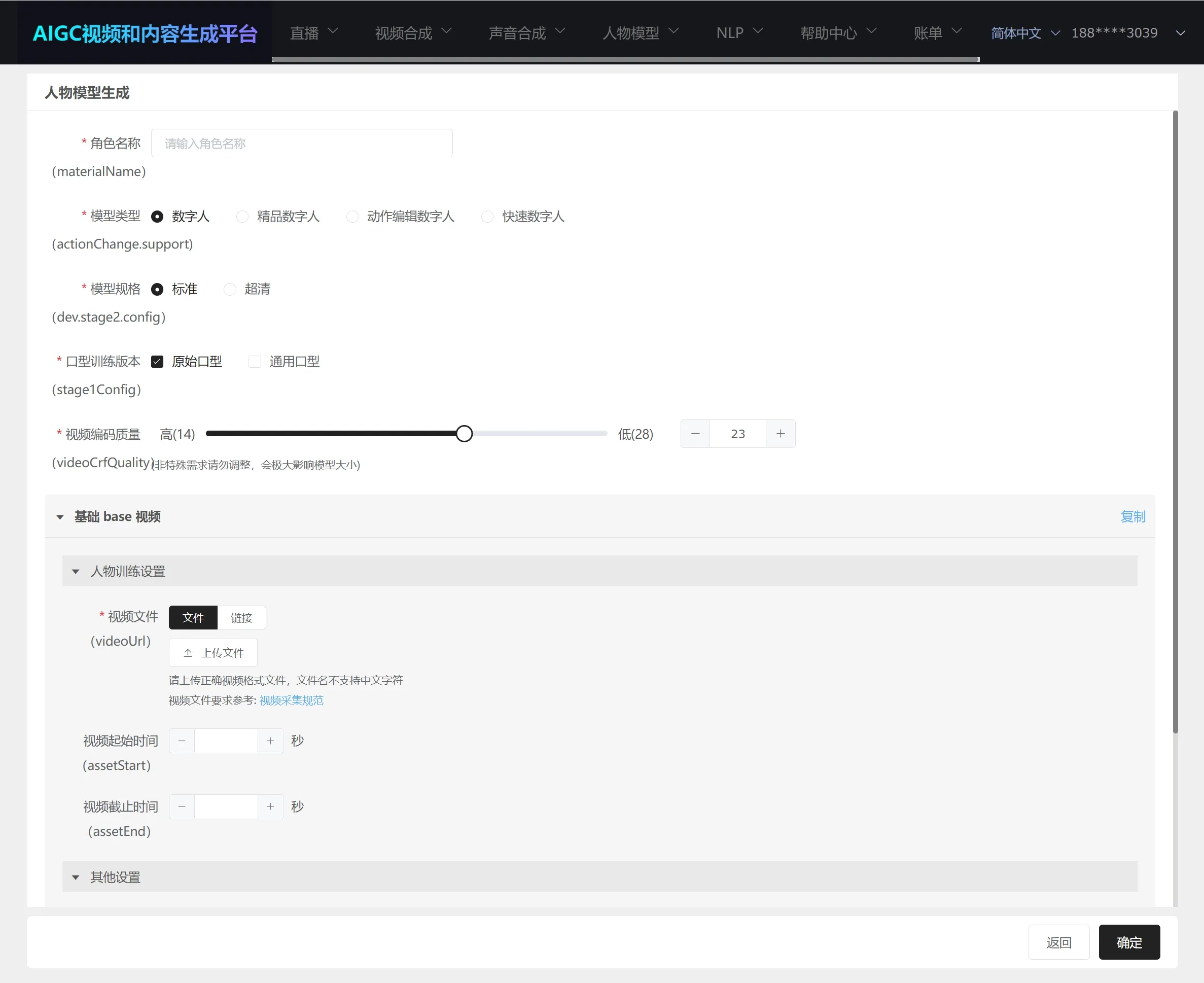
- For detailed parameters, see final parameter explanations.
- After submitting the task, 2K videos typically complete in 4-8 hours.
- Once the task is complete, you can view the completed tasks in "Character Model"—"Character Model Generation." Click "More" to view the generated character image data.
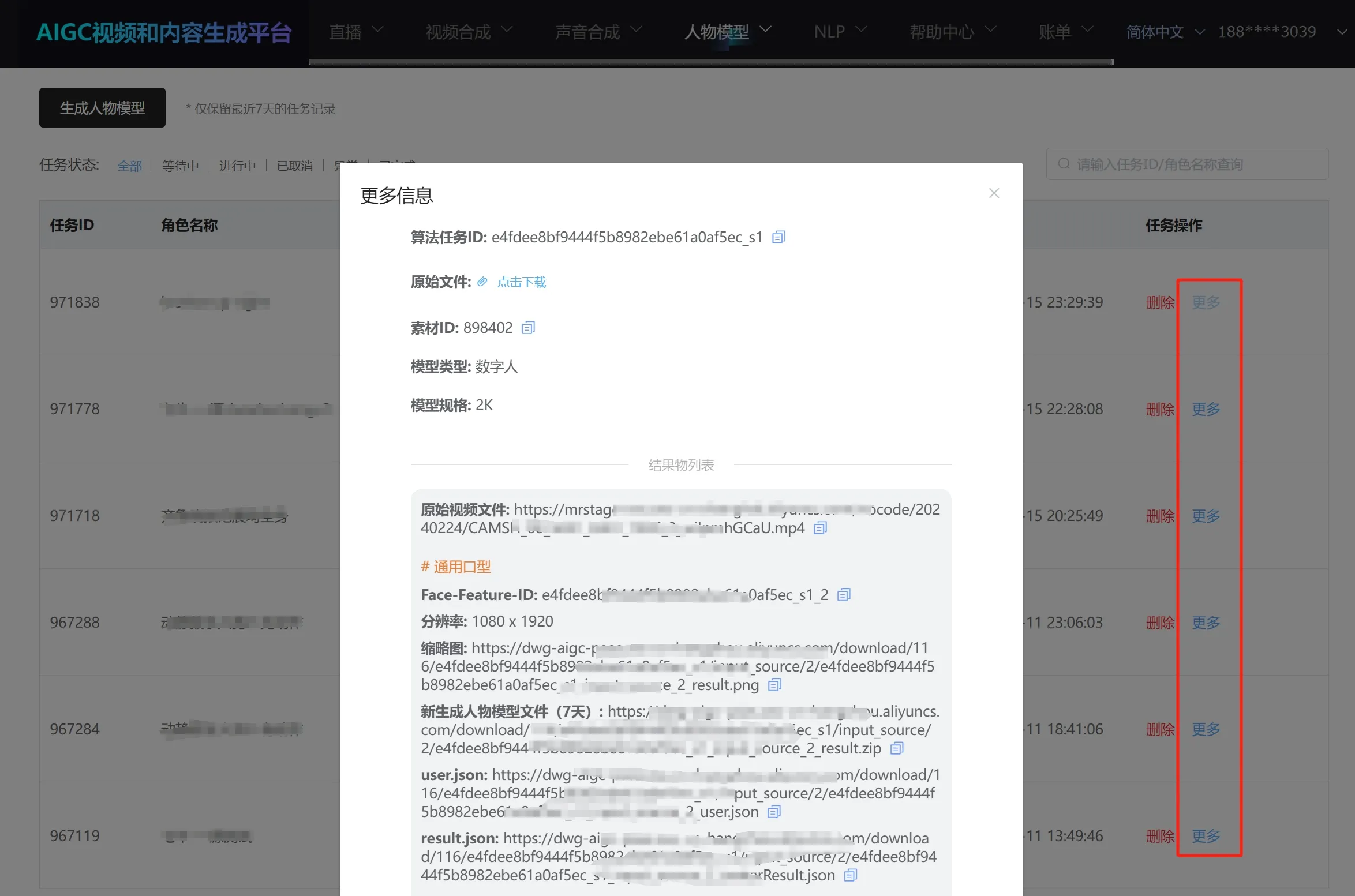
# 5.2 Auxiliary Video/Multi-Scene Video Character Image Training Tasks
- Log in to the platform using a PAAS account.
- Click on "Character Model"—"Character Model Generation" at the top. The current page can view the status of all initiated tasks (limited to tasks within the last 7 days).
- Click on "Character Model Generation" on the left to go to the task model generation page.
- Add the first video, then sequentially add specific information for the other videos.
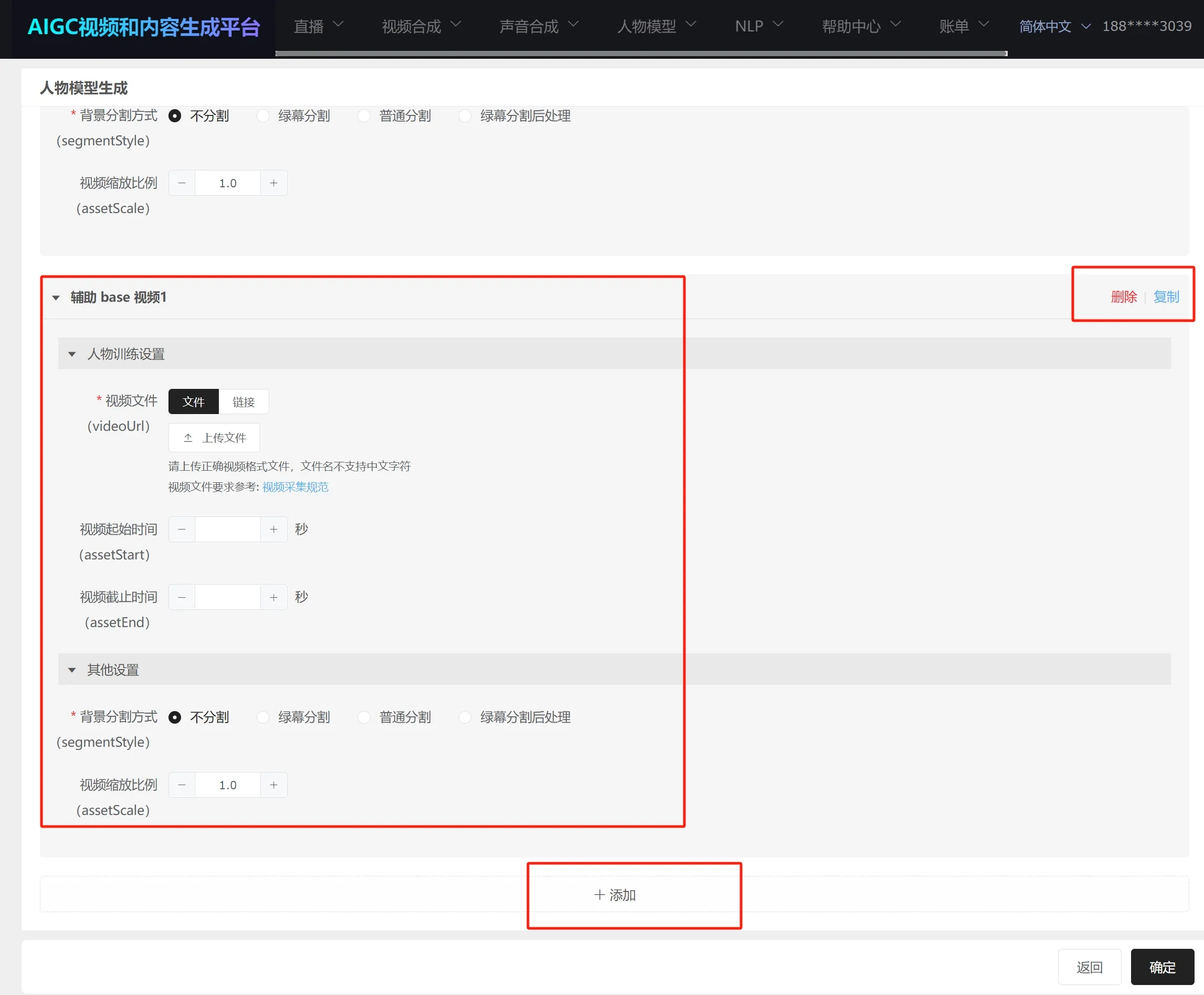
- After submitting the task, multi-video training generally takes a longer time, depending on the number of videos.
- Once the task is complete, you can view the completed tasks in "Character Model"—"Character Model Generation." Click "More" to view the generated character image data.
# 5.3 Parameter Explanation
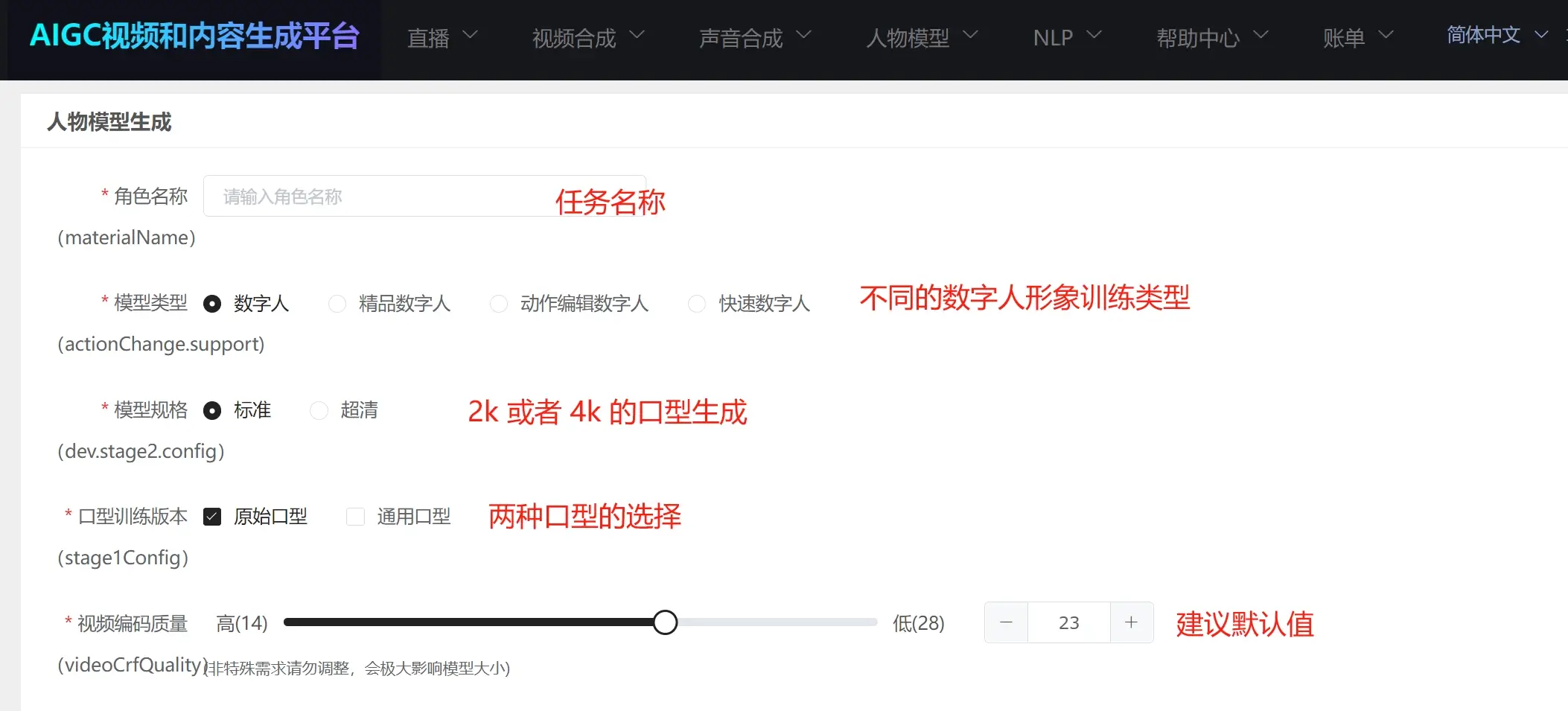
Character Name: The task name for generating character image.
Model Type:
- Digital Human: Standard digital human image generation type supports green screen segmentation, portrait segmentation, and no segmentation for training to generate digital humans.
- Premium Digital Human: Supports silent-state digital humans mainly used in live interactions, 1v1 Q&A, smart customer service, etc., requiring specific filming criteria for the digital human image generation training. Otherwise, poor results may occur.
- Action Editing Digital Human: Supports the digital human with specified actions triggering (currently only supported in video synthesis scenarios; live scenarios do not yet support action-triggered digital humans for live streaming). Specific filming criteria must be met for the digital human image generation training.
- Fast Digital Human: Realistic digital human type, not supporting green screen segmentation or portrait segmentation.
Resolution Type: "Standard" refers to 2K clarity, "Ultra HD" refers to 4K clarity. Note this is the clarity of lip-sync generation, not the video's clarity, which depends on the resolution of the original training video. Generally, if the original training video is 2K, choose "Standard." If 4K, choose "Ultra HD," but note that Ultra HD training takes longer.
Lip-Sync Training Version:
- Original Lip-Sync: Learns the lip-sync from the video and attempts to generate lip-sync based on the person's lip movements.
- Generic Lip-Sync: Attempts to generate lip-sync in a manner generally accepted. Usually, generic lip-sync is better than the original; it is recommended to select both and prioritize generic lip-sync.
Video Encoding Quality: It is recommended to use the default value.
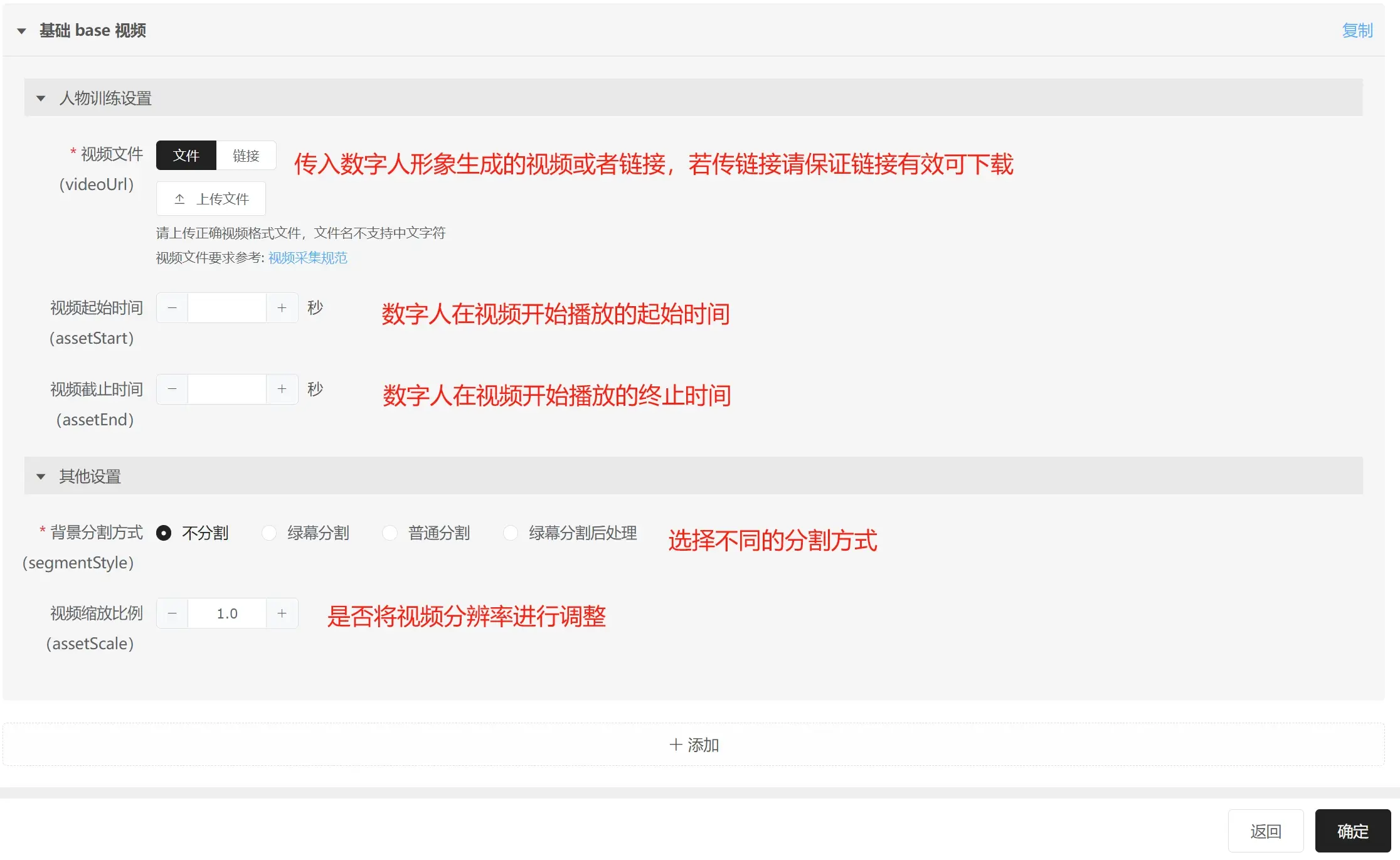
Video File: You can upload local files or provide an OSS link. It is recommended to use an OSS link to prevent upload failures due to large files.
Video Start Time: The start time when the digital human appears in the synthesized video or live stream. (If not filled, the algorithm automatically detects the person's start time in the video.)
Video End Time: The end time when the digital human appears in the synthesized video or live stream. (If not filled, the algorithm automatically detects 5 minutes after the person's start time as the end time.)
In synthesized videos or live streams, the only lip-sync part is generated based on text or audio; all other expressions and body movements are played based on the original video. The playback start time is set above as "Video Start Time"; the end time is set above as "Video End Time." The playback logic is starting from the first frame at "Video Start Time," playing to the last frame at "Video End Time," then reversing to play from the last frame at "Video End Time" back to the first frame at "Video Start Time", and repeating this loop.
Green Screen Segmentation Method:
- No Segmentation: No segmentation is performed, training is based on the original video's people and background. Note that backgrounds cannot be changed in this scenario.
- Green Screen Segmentation: Uses green screen segmentation for removing the green parts of the video, enabling background replacement.
Green screen segmentation works by removing green; care should be taken to avoid having green, anti-green, or transparent green elements in the video, or incorrect segmentation might occur.
General Segmentation: Uses portrait segmentation for extracting the person, allowing background changes. This method is recommended if green screen segmentation cannot be used due to potential interference from accessories, hair, clothes, etc., resulting in uncontrolled effects.
Post-Processing Green Screen Segmentation: First generates the person's image and performs video synthesis, then attempts green screen segmentation. Generally, the above "Green Screen Segmentation" suffices. This method is for exaggerated facial movements where lip sync segmentation works better post-image training.
Video Zoom Ratio: Adjusts the original video resolution. If the original video is 4K and you want a smaller output size, set this accordingly.
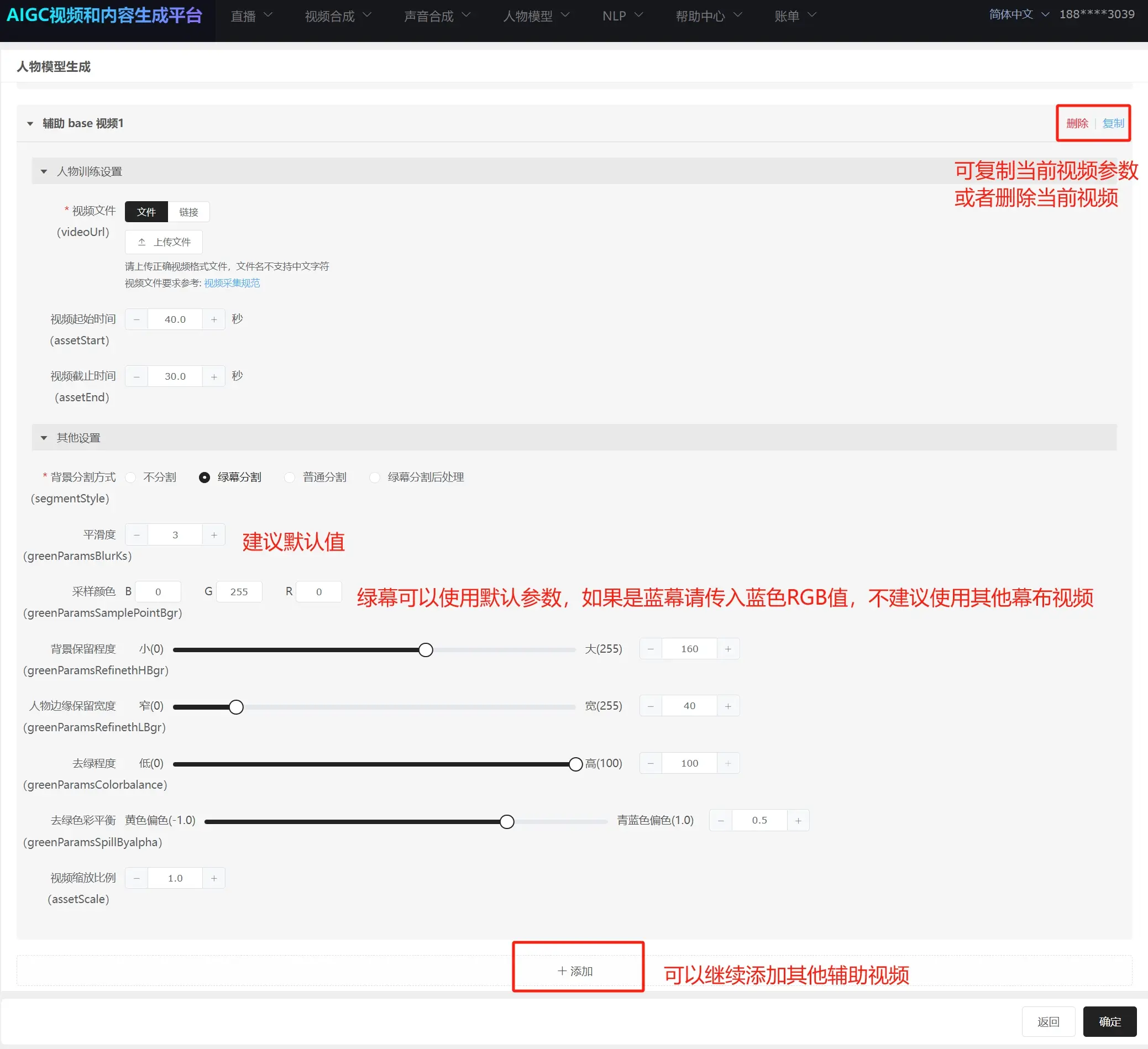
Green Screen Segmentation Parameters:
- Smoothness: Default value suffices.
- Sample Color: The segmentation color, usually green. Blue (RGB 0,0,255) can also be used but other colors are not recommended for best results.
- Background Retention Level: Level of cutoff for the green screen. Lower values cut more green (145, 130, 120, 100, 80, 60, etc.; values too low can lose edge details).
- Person Edge Retention Width: Width of green cutoff at the person's edges. Lower values cut more green (30, 20, 10, etc.; values too low can lose edge details).
- Degree of Green Removal: Default value recommended. If yellow clothes or elements appear, set this to 1 to retain original yellow.
- Green Screen Color Balance: Default value recommended.
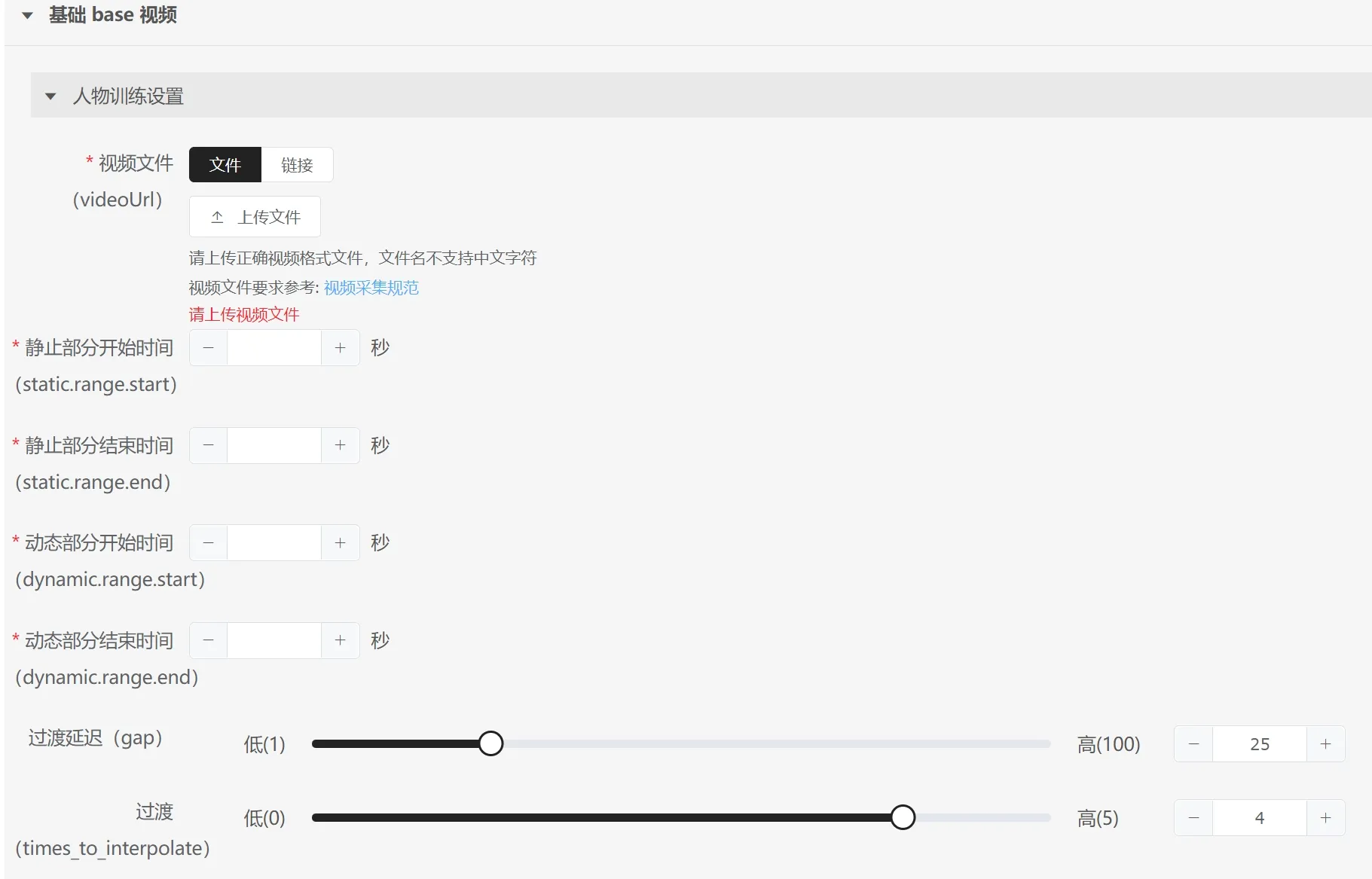
Premium Digital Human Parameters:
- Static Part Start Time: The start time of the silent state, usually the start time of the first 30s of silence.
- Static Part End Time: The end time of the silent state, usually the end time of the 30s of silence.
- Dynamic Part Start Time: The time when the model starts moving.
- Dynamic Part End Time: The time when the model stops moving (select a time near the end of a movement).
- Transition Delay: Default value is recommended.
- Transition: Default value is recommended.
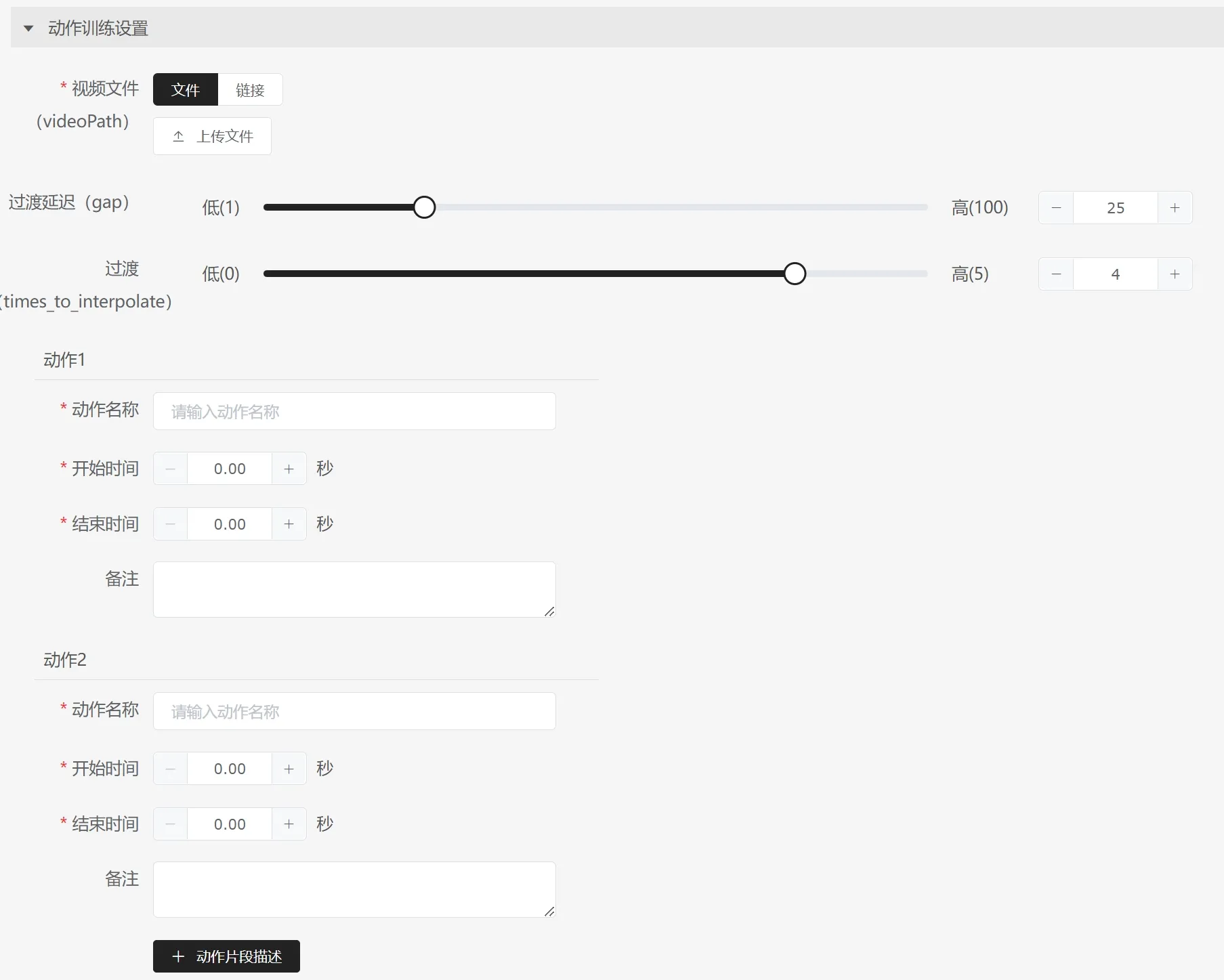
Action Editing Digital Human Parameters:
- Transition Delay: Default value is recommended.
- Transition: Default value is recommended.
- Action 1: Action 1 must fill in the idle time period, which is the initial and ending state for all subsequent actions, and should meet the requirements for approximately 30 seconds.
- Action Name: Name each action, e.g., the first action is "idle." The second and later actions require naming each action in the video.
- Start Time: The start time of the current action.
- End Time: The end time of the current action. Accurate frame times are recommended for better effect expression, e.g., 10s and the 10th frame is 10.4 seconds (25 frames per second, the 10th frame equals 0.4s).
- Remarks: Optional.
# 6. Using the PAAS Platform to Update Digital Human Models
# 6.1 Usage Process
- Log in to the platform using a PAAS account.
- Click on "Character Model"—"Character Model Update" at the top. The current page can view the status of all initiated update tasks (limited to tasks within the last 7 days).
- Click on "Update Character Model" on the left to enter the task model update page.
- Fill in the required update task contents and click OK in the bottom right to submit the task.
- After submitting the task, it is expected to complete in 1-3 hours.
- Once the task is complete, you can view the completed tasks in "Character Model"—"Update Character Model." Click "More" to view the generated character image data.
# 6.2 Precautions
- The original model file and original video file must correspond as a matched set of data, meaning this model file must be output based on this original video file. Do not fill in unrelated original video and model files.
- The digital human's lip-sync information will not be updated; FFID information uses the previous character training generated FFID information.
- **Model Type: When updating a digital human model, only
# 7.4 Potential Failures in Image Training Tasks
Face Missing: Ensure that no frame misses a face. Avoid obstructions by hands or objects over the face and lips;
Multiple Faces: Ensure no frame contains two faces (e.g., faces in posters can cause failures);
Large Angle Faces: It is recommended that the face angle be within 30°. Recognition is supported for large angles (45° or more) but may fail. Example video of large angle walking (opens new window)
Non-Continuous Frames: Non-continuous frames that ensure faces in each frame won't fail, but the resulting training output might have frame jumps. If non-continuous frames have missing faces, it will cause task failure;
Additional video requirements:
- Models can wear makeup during shooting; the digital human generation effect will also include makeup. Alternatively, you can use our post-production makeup effects;
- Very loose hairstyles may affect green screen segmentation (ignore this if not using a green screen);
- Avoid ear accessories or other ornaments with pendants due to potential reflections;
- Avoid hairstyles or oversized glasses that may cover the lower face of the model. The digital human generates only mouth movements, and glasses frames around the lips may cause incorrect mouth shape generation;
- Avoid lip gloss or eye shadow with strong reflections to ensure the green screen segmentation effect and lip generation effect are not compromised;
# 8. Sound Replication Collection Standards
Dear Customer, to help you obtain high-quality recording files, we have prepared a recording guide for you. Please follow the steps below to record, to achieve the best TTS voice replication effect.
# 8.1 Environment Preparation
- Record in a quiet small room (away from traffic noises, crowd noises, and other interference sources). A recording studio is ideal. Avoid recording outdoors, in open offices, or in places with noticeable noise or echo.
- Ensure only one person speaks during the recording to avoid capturing other voices.
# 8.2 Equipment Preparation
- We recommend using high-quality microphones, such as products from Sennheiser, AKG, etc. You can also use newer headsets with microphones. If resources are limited, using the built-in microphone on a newer iPhone is acceptable. Avoid using Bluetooth headphones like AirPods.
- During the recording, ensure you stay within the recommended pickup range of the microphone and maintain a consistent distance.
# 8.3 Pronunciation Requirements
- Do not read the document repetitively; read the script once;
- Try to maintain the same speech speed, tone, and emotional state while recording; pronunciations should be accurate and clear, matching the expected voice clone's tone and pitch;
- Keep volume moderate to avoid popping sounds and noise when too close to the microphone and faint sound when too far;
- Avoid breathing sounds, inhaling sounds, and filler words like "um" and "ah" in the middle of sentences;
- Use lossless audio format as much as possible;
- Noise reduction must be done to ensure the audio has no environmental noise (otherwise, the cloned voice will have noise).
# 8.4 Sound Replication Considerations
- It is recommended to record at least 20 minutes of effective audio; 30 minutes is preferable. Longer recordings contribute to more accurate voice replication.
- For longer recordings, break them into segments with rest periods in between. However, maintain consistent speed, volume, pitch, and tone across all recordings.
- An audio file for voice authorization is required. See the appendix for file requirements.
- For large-model voice replication, it is recommended to record 50-90 seconds of effective audio.
# 8.5 Format Requirements
- The audio files for voice replication and authorization can be in the following formats: wav, mp3, m4a, mp4, mov, aac.
# 8.6 Appendix
The user authorization audio file is used to confirm that the user has authorized us to perform voice replication. The audio content must be recorded following the specified script.
- Here is an example in Chinese:
xx (speaker’s name) confirms that my voice will be used by xx (company name) to create and use a synthetic version of my voice.
Authorization files can support other languages, as detailed below:
- English:
I [state your first and last name] am aware that recordings of my voice will be used by [state the name of the company] to create and use a synthetic version of my voice.
- Japanese:
私(名前を記入)は自身の音声を(会社名を記入)が使用し、合成音声を作り使用されることに同意します。
- Korean:
나는 [본인의 이름을 말씀하세요] 내 목소리의 녹음을 이용해 합성 버전을 만들어 사용된다는 것을 [회사 이름을 말씀하세요]알고 있습니다.
# 9. Using PAAS Platform for Voice Replication
- Log in to the platform using a PAAS account;
- Click on "Voice Synthesis" at the top—"TTS Personal Voice Model Generation-Qid (Recommended)"—"Click Generate";

- Fill in the task information and upload the corresponding audio file;

- Click "Confirm" to create the voice replication task;

- Upon task completion, click "More" to download the result file;

- The result file contains the corresponding voice qid and other information. Please retain this information for future requests.
Taking the TTS6 output as an example, the result file is as follows:
{
"msg": "task is finished",
"stage": "deployment",
"voice": {
"qid": "eQz_IP:AEAyxxxxxxxxRSUpItdQ0szE10LCzSU3QtDS0tjVLMDMK",
"name": "-tts6",
"gender": 1,
"languages": [
"en-US",
"zh-CN",
"af-ZA",
"am-ET",
"de-AT",
"de-CH",
"de-DE",
"el-GR",
"en-AU",
"en-CA",
"en-GB",
"en-IE",
"en-IN",
"fr-BE",
"zh-HK",
"zh-TW",
"zu-ZA"
]
},
"taskId": "tts6-051370ad-96cd-43a4-8a42-8fcdfa8658e6",
"tenant": "116",
"modelUrl": "",
"taskType": "TTS6",
"taskStatus": 5,
"stageStatus": 5,
"updatedTime": "2024-06-25T13:11:10.000194872Z",
"sampleAudioUrl": ""
}
# 10. Considerations for Sound Replication
- TTS3 voice cloning takes approximately 20 hours;
- TTS6 voice cloning is estimated to take less than 1 hour;
- Ensure the recording duration for voice replication audio meets the corresponding requirements: at least 20 minutes for TTS3 (30 minutes recommended); 1 minute recommended for TTS6 but should not exceed 90 seconds;
- Strictly follow the corresponding script for the authorization audio, and ensure it is voiced by the same person as the voice replication audio;
- All recordings must be noise-reduced. Environmental noise will result in significant deviations in TTS replication from the original voice;
- TTS3 only replicates Mandarin voices; TTS6 can replicate voices in multiple languages, including Mandarin and English, but with less fidelity compared to TTS3.